Binary Prediction with a Rainfall Dataset

이 글은 Kaggle의 “Binary Prediction with a Rainfall Dataset” 경진대회를 다룹니다.#
- Kaggle 링크: Binary Prediction with a Rainfall Dataset
- 소스 코드: GitHub Repository
1. 환경 설정 및 데이터 로드#
필요한 라이브러리 임포트#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score, roc_auc_score, roc_curve
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
import xgboost as xgb
데이터 로드#
# 훈련 및 테스트 데이터 로드
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
2. 데이터 탐색 (EDA)#
기본 정보 확인#
print("train data:", train_data.shape) # (2190, 13)
print("train data info:\n", train_data.info())
print("train data describe:\n", train_data.describe())
print("train data isnull:\n", train_data.isnull().sum())
print("test data isnull:\n", test_data.isnull().sum())
print("train data rainfall value_counts:\n", train_data['rainfall'].value_counts())
print(f"train data rainfall value_counts(normalize):\n{train_data['rainfall'].value_counts(normalize=True)}")
데이터 구조 분석#
데이터셋의 정보를 확인하면 다음과 같습니다:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2190 entries, 0 to 2189
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 2190 non-null int64
1 day 2190 non-null int64
2 pressure 2190 non-null float64
3 maxtemp 2190 non-null float64
4 temparature 2190 non-null float64
5 mintemp 2190 non-null float64
6 dewpoint 2190 non-null float64
7 humidity 2190 non-null float64
8 cloud 2190 non-null float64
9 sunshine 2190 non-null float64
10 winddirection 2190 non-null float64
11 windspeed 2190 non-null float64
12 rainfall 2190 non-null int64
dtypes: float64(10), int64(3)
데이터 특성 설명#
id: 고유 식별자day: 일자 (1 ~ 365)pressure: 기압 (hPa)maxtemp: 최고 온도 (°C)temparature: 평균 온도 (°C) (오타인 듯하지만 원본 데이터를 따름)mintemp: 최저 온도 (°C)dewpoint: 이슬점 (°C)humidity: 습도 (%)cloud: 운량 (%)sunshine: 일조 시간 (시간)winddirection: 풍향 (각도)windspeed: 풍속 (km/h)rainfall: 강수 여부 (0 = 비 안옴, 1 = 비 옴) - 타겟 변수
특성별 데이터 분석#
describe() 결과를 바탕으로 각 특성을 분석하면:
day:
- 약 6년(2190 ÷ 365 ≈ 6)의 데이터
- 날짜가 골고루 분포됨
pressure:
- 평균값: 1013.6 hPa (표준 대기압 1013.25 hPa에 가까움)
- 표준편차: 5.66 (변동성이 크지 않음)
- 범위: 999 ~ 1034.6 hPa (전형적인 기압 분포)
- 강수와 밀접한 관련이 있는 중요 변수
maxtemp:
- 범위: 10.4°C ~ 36.0°C
- 평균: 26.37°C, 중앙값: 27.8°C
- 표준편차: 5.65 (적당한 변동성, 비교적 대칭적 분포)
temparature:
- 범위: 7.4°C ~ 31.5°C
- 평균: 23.95°C, 중앙값: 25.5°C
- 표준편차: 5.22 (적당한 변동성)
- 중앙값이 평균보다 높아 데이터가 왼쪽으로 약간 치우침
mintemp:
- 범위: 4°C ~ 29.8°C
- 평균: 22.17°C, 중앙값: 24.85°C
- 표준편차: 5.06 (적당한 변동성)
- 중앙값이 평균보다 높아 약간의 비대칭성 존재
dewpoint:
- 범위: -0.3°C ~ 26.7°C
- 평균: 20.45°C (습도가 높음을 시사)
- 표준편차: 5.29 (적당한 변동성)
- 강수와 직접적으로 연관될 수 있는 중요 변수
humidity:
- 범위: 39% ~ 98%
- 평균: 82.04% (매우 높은 습도)
- 표준편차: 7.8 (변동성이 크지 않음)
- 1사분위수가 77%로, 대부분의 날이 습한 환경임을 시사
- 높은 습도는 강수 가능성을 높임
cloud:
- 범위: 2% ~ 100%
- 평균: 75.52% (높은 구름량)
- 표준편차: 18.03 (변동성이 큼)
- 중앙값이 평균보다 높아 데이터가 왼쪽으로 치우침
- 구름량은 강수와 밀접한 관련이 있음
sunshine:
- 범위: 0 ~ 12.1시간
- 평균: 3.74시간 (낮은 일조 시간)
- 표준편차: 3.63 (큰 변동성)
- 25%의 일조 시간이 0.4시간으로 매우 낮아 흐린 날이 많았음을 시사
- 낮은 일조 시간은 구름량과 연관되며, 이는 강수와 연관됨
winddirection:
- 범위: 10° ~ 300°
- 평균: 104.86° (동쪽~남동쪽)
- 표준편차: 80 (풍향의 다양성이 큼)
windspeed:
- 범위: 4.4 ~ 59.5 km/h
- 평균: 21.8 km/h
- 표준편차: 9.9 (적당한 변동성)
- 최대값 59.5 km/h는 강한 바람으로 이상치일 가능성 있음
rainfall:
- 평균: 75.34% (약 75%의 날에 비가 옴)
- 모든 사분위수가 1로, 강수 발생 빈도가 높음
결측치 확인#
- 훈련 데이터: 결측치 없음
- 테스트 데이터:
winddirection에 결측치 1개 존재 (예측 시 처리 필요)
3. 상관관계 분석#
correlation = train_data.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(correlation, annot=True, cmap="coolwarm", linewidths=0.5)
plt.title('correlation between features')
plt.tight_layout()
plt.show()
plt.close()
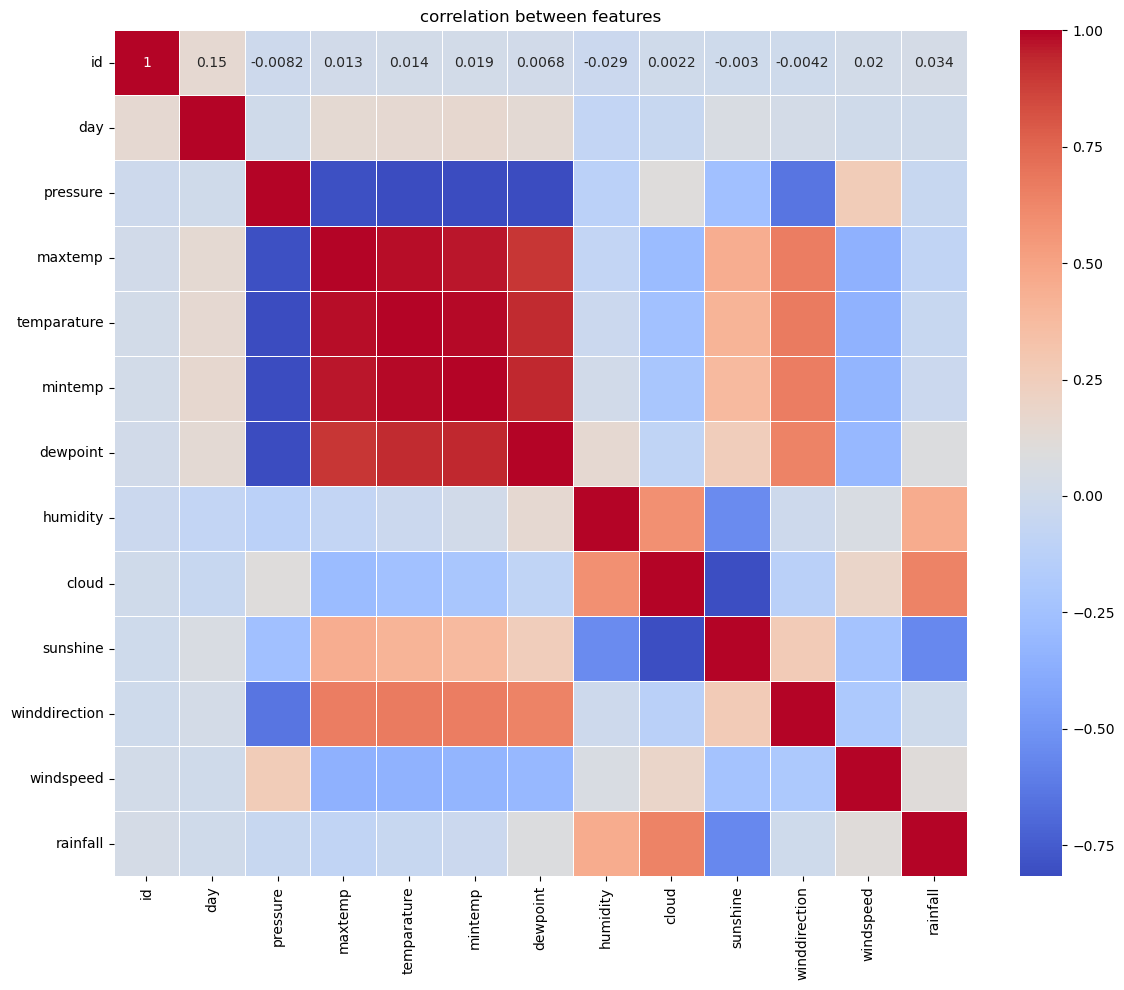
상관관계 분석의 중요성#
상관관계 분석은 머신러닝에서 다음과 같은 이유로 중요합니다:
특성 선택 및 차원 축소: 높은 상관관계를 가진 변수들은 비슷한 정보를 제공할 가능성이 높아, 중복된 정보를 제거해 모델의 복잡성을 줄일 수 있습니다.
다중공선성 방지: 독립 변수 간의 높은 상관관계는 모델의 안정성과 해석력을 저하시킬 수 있습니다. 상관관계 분석으로 이를 사전에 감지할 수 있습니다.
모델 해석력 향상: 특정 변수와 타겟 변수 간의 관계를 이해하여 모델의 예측 결과를 더 잘 해석할 수 있습니다.
데이터 이해: 데이터의 구조와 패턴을 파악하여 적절한 모델링 전략을 수립할 수 있습니다.
상관관계 히트맵 해석#
히트맵에서 빨간색은 양의 상관관계, 파란색은 음의 상관관계를 나타냅니다. 주요 관계는 다음과 같습니다:
강한 양의 상관관계:
maxtemp와temperature,mintemp,dewpointtemperature와mintemp,dewpointmintemp와dewpoint
강한 음의 상관관계:
pressure와maxtemp,temperature,mintemp,dewpoint
타겟 변수와의 상관관계#
rainfall_corr = correlation['rainfall'].sort_values(ascending=False)
print("correlation between rainfall and each features:")
print(rainfall_corr)
결과:
rainfall 1.000000
cloud 0.641191
humidity 0.454213
windspeed 0.111625
dewpoint 0.081965
id 0.033674
day -0.000462
winddirection -0.006939
mintemp -0.026841
temparature -0.049660
pressure -0.049886
maxtemp -0.079304
sunshine -0.555287
rainfall과 가장 상관관계가 높은 특성:
- 양의 상관관계:
cloud(0.64),humidity(0.45) - 음의 상관관계:
sunshine(-0.56)
4. 특성 공학 (Feature Engineering)#
온도 차이 특성 추가#
# 온도 차이 (대기 불안정성 지표)
train_data['temp_diff'] = train_data['maxtemp'] - train_data['mintemp']
test_data['temp_diff'] = test_data['maxtemp'] - test_data['mintemp']
온도 차이는 대기의 불안정성을 나타내며, 차이가 클수록 비가 올 확률이 높아질 수 있습니다.
기온-이슬점 차이 특성 추가#
# 기온과 이슬점 차이 (습도 지표)
train_data['temp_dewpoint_diff'] = train_data['temparature'] - train_data['dewpoint']
test_data['temp_dewpoint_diff'] = test_data['temparature'] - test_data['dewpoint']
기온과 이슬점의 차이가 작을수록 공기가 습하고 강수 가능성이 높아집니다.
주기적 특성 인코딩#
# 날짜의 주기성 인코딩
train_data['day_sin'] = np.sin(2 * np.pi * train_data['day'] / 365.25)
train_data['day_cos'] = np.cos(2 * np.pi * train_data['day'] / 365.25)
test_data['day_sin'] = np.sin(2 * np.pi * test_data['day'] / 365.25)
test_data['day_cos'] = np.cos(2 * np.pi * test_data['day'] / 365.25)
날짜는 주기적 특성을 가집니다. 예를 들어, 12월 31일과 1월 1일은 수치상으로는 차이가 크지만 실제로는 연속적입니다. 사인과 코사인 변환으로 이러한 주기성을 모델에 전달합니다.
불필요한 특성 제거#
# 훈련/테스트 특성 준비
train_features = train_data.drop(['id', 'day', 'rainfall'], axis=1)
test_features = test_data.drop(['id', 'day'], axis=1)
id와 day는 예측에 불필요하며, rainfall은 예측하려는 타겟 변수입니다.
5. 모델 훈련 및 평가#
데이터 분할#
# 타겟 변수 추출
train_target = train_data['rainfall']
# 훈련/검증 데이터 분할
X_train, X_val, y_train, y_val = train_test_split(
train_features, train_target, test_size=0.2, random_state=42, stratify=train_target
)
특성 스케일링#
# 표준화 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_val_scaled = scaler.transform(X_val)
test_scaled = scaler.transform(test_features)
print("train data shape:", X_train.shape)
print("validation data shape:", X_val.shape)
print("test data shape:", test_features.shape)
표준화는 각 특성의 평균을 0, 표준편차를 1로 맞추는 작업으로, 모델의 성능 향상에 도움이 됩니다.
모델 비교 및 평가#
# 다양한 모델 정의
models = {
'Logistic Regression': LogisticRegression(max_iter=1000, random_state=42),
'Random Forest': RandomForestClassifier(n_estimators=100, random_state=42),
'Gradient Boosting': GradientBoostingClassifier(n_estimators=100, random_state=42),
'XGBoost': xgb.XGBClassifier(n_estimators=100, random_state=42)
}
results = {}
# 각 모델 훈련 및 평가
for name, model in models.items():
# 모델 훈련
model.fit(X_train_scaled, y_train)
# 검증 데이터 예측
val_pred = model.predict(X_val_scaled)
val_prob = model.predict_proba(X_val_scaled)[:, 1] if hasattr(model, 'predict_proba') else None
# 성능 평가
accuracy = accuracy_score(y_val, val_pred)
report = classification_report(y_val, val_pred)
cm = confusion_matrix(y_val, val_pred)
auc = roc_auc_score(y_val, val_prob) if val_prob is not None else None
# 결과 저장
results[name] = {
'model': model,
'accuracy': accuracy,
'auc': auc,
'report': report,
'confusion_matrix': cm
}
# 결과 출력
print(f"\n{name} model performance:")
print(f"Accuracy: {accuracy:.4f}")
print(f"AUC: {auc:.4f}" if auc is not None else "AUC: None")
print("\nClassification Report:")
print(report)
# 혼동 행렬 시각화
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.title(f'{name} - Confusion Matrix')
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()
plt.close()
모델 설명:#
- Logistic Regression: 선형 회귀 기반의 분류 모델로, 간단하고 해석이 용이합니다.
- Random Forest: 여러 의사결정 트리를 결합한 앙상블 모델로, 과적합 방지에 효과적입니다.
- Gradient Boosting: 부스팅 기법을 사용한 앙상블 모델로, 점진적으로 오류를 수정합니다.
- XGBoost: Gradient Boosting의 최적화된 버전으로, 속도와 성능이 우수합니다.
모델별 성능 평가#
1. Logistic Regression#
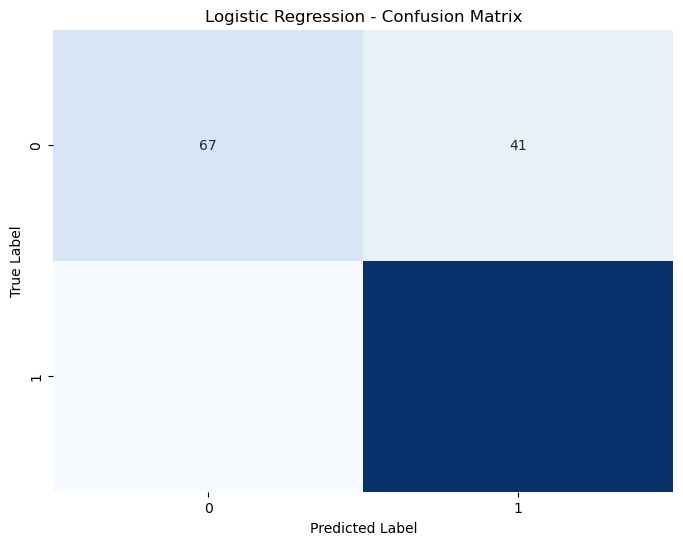
- 정확도: 0.8653
- AUC: 0.8799
- 클래스별 성능:
- 클래스 0 (비 안옴): 정밀도 0.79, 재현율 0.62, F1-score 0.69
- 클래스 1 (비 옴): 정밀도 0.88, 재현율 0.95, F1-score 0.91
- 혼동 행렬 분석:
- True Negatives (TN): 67
- False Positives (FP): 41
- False Negatives (FN): 17
- True Positives (TP): 313
- 해석: 클래스 1(비 옴)에 대한 예측이 뛰어나지만, 클래스 0(비 안옴)에 대한 재현율이 낮습니다.
2. Random Forest#
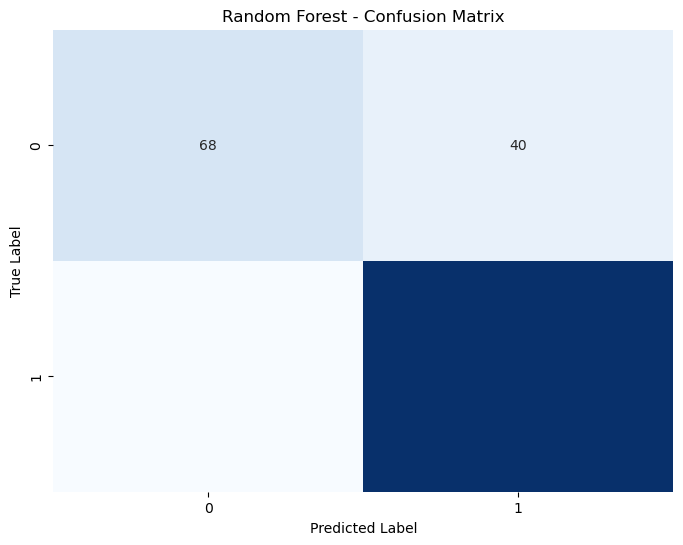
- 정확도: 0.8676
- AUC: 0.8667
- 클래스별 성능:
- 클래스 0: 정밀도 0.79, 재현율 0.63, F1-score 0.70
- 클래스 1: 정밀도 0.89, 재현율 0.95, F1-score 0.92
- 혼동 행렬 분석:
- True Negatives (TN): 68
- False Positives (FP): 40
- False Negatives (FN): 17
- True Positives (TP): 313
- 해석: 모든 지표에서 균형 잡힌 성능을 보이며, 정확도가 가장 높습니다.
3. Gradient Boosting#
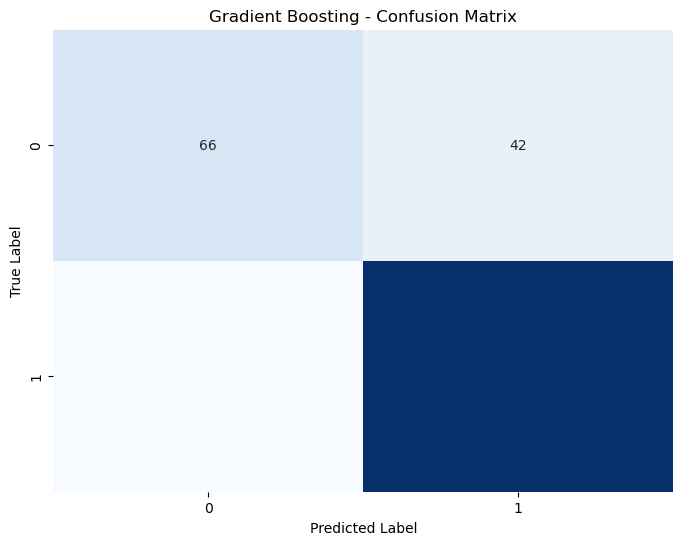
- 정확도: 0.8584
- AUC: 0.8589
- 클래스별 성능:
- 클래스 0: 정밀도 0.77, 재현율 0.61, F1-score 0.68
- 클래스 1: 정밀도 0.88, 재현율 0.94, F1-score 0.91
- 혼동 행렬 분석:
- True Negatives (TN): 66
- False Positives (FP): 42
- False Negatives (FN): 20
- True Positives (TP): 310
- 해석: 클래스 0의 재현율이 낮아 다른 모델보다 성능이 약간 떨어집니다.
4. XGBoost#
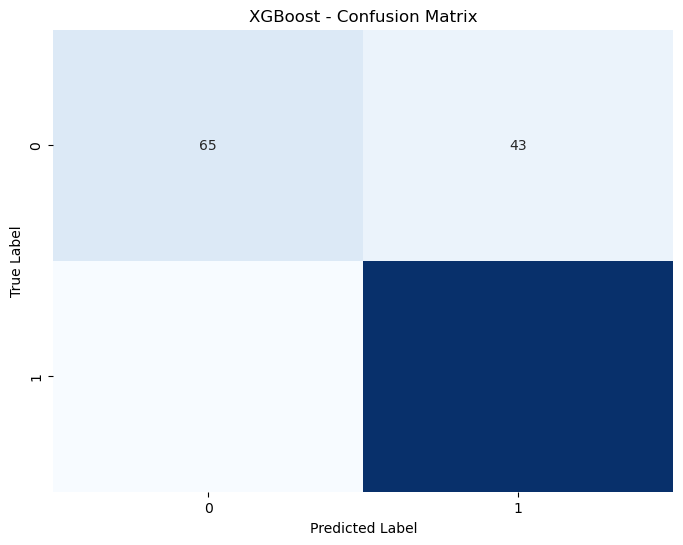
- 정확도: 0.8425
- AUC: 0.8420
- 클래스별 성능:
- 클래스 0: 정밀도 0.71, 재현율 0.60, F1-score 0.65
- 클래스 1: 정밀도 0.88, 재현율 0.92, F1-score 0.90
- 해석: 네 모델 중 정확도와 AUC가 가장 낮으며, 클래스 0의 예측이 다소 약합니다.
참고: 혼동 행렬 이미지와 보고서 간 불일치가 있을 수 있으며, 이는 데이터 처리 과정에서 발생한 차이로 보임
성능 지표 설명#
클래스 0과 1: 이진 분류에서 클래스 0은 ‘비가 오지 않음’, 클래스 1은 ‘비가 옴’을 의미합니다.
AUC(Area Under the Curve): ROC 곡선 아래 면적으로, 모델의 분류 성능을 나타냅니다.
- 1에 가까울수록: 완벽한 분류 능력
- 0.5: 무작위 예측 수준
- AUC가 높을수록 모델이 클래스를 잘 구분합니다.
최적 모델 선택#
# 최고 성능 모델 선택
best_model_name = max(results, key=lambda x: results[x]['accuracy'])
best_model = results[best_model_name]['model']
print(f"best model: {best_model_name}")
print(f"accuracy: {results[best_model_name]['accuracy']:.4f}")
print(f"AUC: {results[best_model_name]['auc']:.4f}" if results[best_model_name]['auc'] is not None else "AUC: None")
결과:
best model: Random Forest
accuracy: 0.8676
AUC: 0.8667
Random Forest가 가장 높은 정확도를 보이며, AUC도 우수하여 최적 모델로 선정되었습니다.
6. 특성 중요도 분석#
# 특성 중요도 시각화 (트리 기반 모델)
if hasattr(best_model, 'feature_importances_'):
feature_importances = pd.DataFrame({
'feature': train_features.columns,
'importance': best_model.feature_importances_
}).sort_values('importance', ascending=False)
plt.figure(figsize=(12, 8))
sns.barplot(x='importance', y='feature', data=feature_importances)
plt.title(f'{best_model_name} - feature importance')
plt.tight_layout()
plt.show()
plt.close()
print("\nfeature importance:")
print(feature_importances)
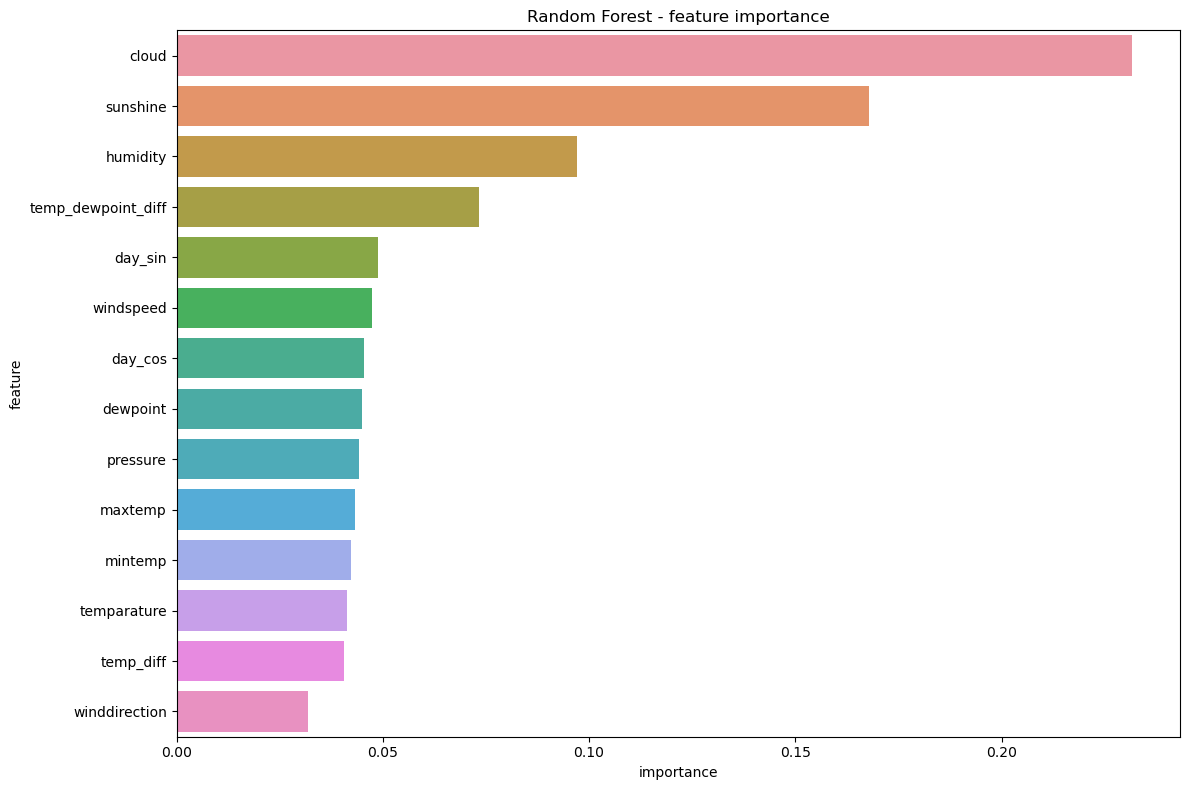
특성 중요도 해석#
가장 중요한 특성:
- cloud (0.232): 구름량이 가장 중요한 예측 변수
- sunshine (0.168): 일조 시간이 두 번째로 중요
- humidity (0.097): 습도가 세 번째로 중요
- temp_dewpoint_diff (0.073): 온도와 이슬점 차이도 중요한 변수
이는 상관관계 분석 결과와도 일치하며, 직관적으로도 타당합니다.
7. 하이퍼파라미터 튜닝#
# 하이퍼파라미터 그리드 정의
if best_model_name == 'Random Forest':
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
elif best_model_name == 'Gradient Boosting':
param_grid = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.05, 0.1],
'max_depth': [3, 5, 7],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
elif best_model_name == 'XGBoost':
param_grid = {
'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.05, 0.1],
'max_depth': [3, 5, 7],
'subsample': [0.7, 0.8, 0.9],
'colsample_bytree': [0.7, 0.8, 0.9]
}
else: # Logistic Regression
param_grid = {
'C': [0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2'],
'solver': ['liblinear', 'saga']
}
# 그리드 서치 수행
grid_search = GridSearchCV(
estimator=best_model,
param_grid=param_grid,
cv=5,
scoring='accuracy',
verbose=1,
n_jobs=-1
)
print("running grid search...")
grid_search.fit(X_train, y_train)
print(f"optimal hyperparameter: {grid_search.best_params_}")
print(f"optimal cross-validation score: {grid_search.best_score_:.4f}")
그리드 서치 (Grid Search)#
그리드 서치는 여러 하이퍼파라미터 조합을 시도하여 최적의 조합을 찾는 기법입니다:
- 하이퍼파라미터: 모델 학습 전 설정하는 값 (예: 트리 깊이, 트리 개수 등)
- 교차 검증(CV=5): 데이터를 5개 폴드로 나누어 반복 평가하여 일반화 성능을 측정
- 평가 지표: 정확도(accuracy)
8. 최종 모델 훈련 및 예측#
# 최적 파라미터로 모델 재학습
best_model = grid_search.best_estimator_
best_model.fit(X_train_scaled, y_train)
# 검증 데이터로 성능 평가
y_pred = best_model.predict(X_val_scaled)
y_prob = best_model.predict_proba(X_val_scaled)[:, 1] if hasattr(best_model, 'predict_proba') else None
print(f"\nbest model performance (validation data):")
print(f"Accuracy: {accuracy_score(y_val, y_pred):.4f}")
print(f"AUC: {roc_auc_score(y_val, y_prob):.4f}" if y_prob is not None else "AUC: None")
print("\nClassification Report:")
print(classification_report(y_val, y_pred))
# 테스트 데이터 예측
print("\n# predict with test data")
test_pred = best_model.predict(test_scaled)
test_prob = best_model.predict_proba(test_scaled)[:, 1] if hasattr(best_model, 'predict_proba') else None
# 제출 파일 생성
submission = pd.DataFrame({
'id': test_data['id'],
'rainfall': test_pred
})
# 예측 결과 분포 확인
print("predict result distribution:")
print(submission['rainfall'].value_counts())
# 제출 파일 저장
submission.to_csv('submission.csv', index=False)
print("submission file created: 'submission.csv'")
테스트 결과 분포#
predict result distribution:
rainfall
1 580
0 150
Name: count, dtype: int64
테스트 데이터의 약 79.5%가 강수 발생(클래스 1)으로 예측되었으며, 이는 훈련 데이터의 클래스 분포(약 75%)와 유사합니다.
결론#
이 프로젝트에서는 기상 데이터를 활용하여 강수 여부를 예측하는 이진 분류 모델을 개발했습니다. 다양한 모델 중 Random Forest가 가장 우수한 성능을 보였으며, 하이퍼파라미터 튜닝을 통해 모델을 최적화했습니다.
특성 중요도 분석 결과, 구름량(cloud), 일조 시간(sunshine), 습도(humidity)가 강수 예측에 가장 중요한 역할을 하는 것으로 나타났습니다. 이는 실제 기상학적 관점에서도 타당한 결과입니다.
최종 모델은 약 87%의 정확도로 강수 여부를 예측할 수 있었습니다.
public score는 0.74617점정도 나옵니다
