Levels of Abstraction
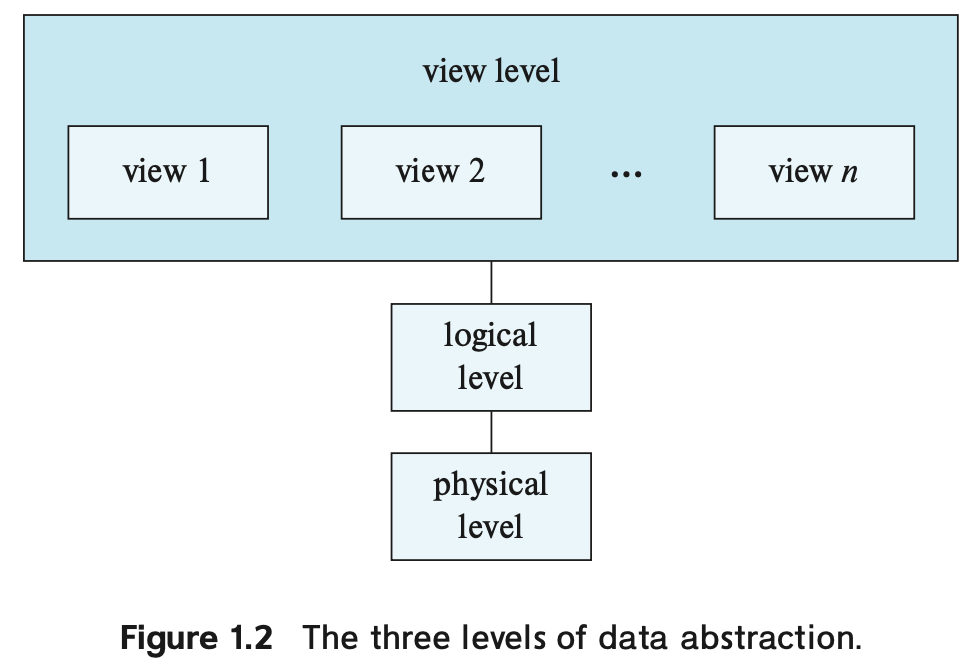
Levels of Abstraction#
1. Physical Level:
어떤 수준인가? 데이터베이스의 가장 낮은 추상화 단계. 이 단계에서는 데이터가 실제로 어떻게 저장되는지에 초점을 맞춤. 즉 컴퓨터의 하드디스크나 메모리 같은 물리적인 저장 장치에서 데이터가 어떻게 관리되는지를 다룸
주요 특징
- 데이터가 파일 형태로 어떻게 조직되는지, 어떤 index를 사용하는지, 데이터를 압축하는 방법 등을 결정함
- ex) 학생 정보 라는 데이터가 하드디스크의 특정 위치에 파일로 저장되고, 빠른 검색을 위해 index가 설정되어 있다
누가 다룸? Database Administrator(DBA)나 시스템 엔지니어가 다룸. 일반 사용자는 이 복잡한 물리적 세부사항을 알 필요가 없음
비유 도서관에서 책이 실제로 어떤 선반, 어떤 상자에 있는지 관리하는 것. 책을 읽는 사람은 몰라도 됨
2. Logical Level
어떤 수준인가? 데이터가 무엇인지, 그리고 데이터들 사이의 관계가 어떻게 되는지를 설명함. 물리적인 저장 방식은 신경쓰지 않고, 데이터의 구조와 의미에 집중함
주요 특징
- table column, row 같은 간단한 구조로 데이터를 표현
- ex) “학생” 테이블에 이름, 학번, 전공 같은 column이 있고, “수업” 테이블과 연결되어 있다고 정의할 수 있음
- 물리적 수준의 세부 사항 (어떤 파일에 저장되는지)은 숨겨져 있음. 이를 Physical Data Independence라고 함. 즉, 저장 방식이 바뀌어도 논리적 수준에는 영향을 주지 않음
누가 다룸? 데이터베이스 설계자나 개발자가 주로 이 수준에서 작업함. 사용자는 여전히 복잡한 기술적 세부 사항을 몰라도 됨
비유 도서관에서 책의 목록을 작성하고, 어떤 책이 어떤 주제와 관련 있는지를 정리하는 것. 책이 실제로 어디에 있는지는 신경쓰지 않고, 책의 내용과 구조만 다룸
3. View Level
어떤 수준인가? 사용자가 데이터를 어떻게 보는지에 초점을 맞춤. 전체 DB중에서 사용자에게 필요한 부분만 보여주고, 원하는 방식으로 데이터를 표현함
주요 특징
- 모든 사용자가 같은 데이터를 다르게 볼 수 있음. 예를 들어 학생은 자신의 성적만 볼 수 있고, 교수는 전체 학생의 성적을 볼 수 있음
- 특정 열이나 요약된 데이터만 보여줄 수도 있음
- 논리적 수준이 바뀌어도 뷰 수준에 영향을 주지 않는 Logical Data Independence을 제공함
누가 다룸? 일반 사용자나 응용 프로그램이 주로 다룸. 사용자는 복잡한 데이터 구조를 알 필요 없이 자신에게 필요한 정보만 쉽게 볼 수 있음
비유 도서관에서 학생은 내가 빌린 책 목록만 보고 사서는 모든 대출 기록을 볼 수 있는 것과 비슷함. 같은 데이터지만 각자의 필요에 맞게 봄
출처: Database System Concept - 1.3 Data View