The Structure of Agents (1)
이 사진 아닌 것 같긴 한데 구글에 the structure of agents 치면 나오길래…
에이전트의 내부 작동 방식#
보통 에이전트(인공지능 주체)를 설명할 때 주로 행동에 초점을 맞춰서 이야기함
즉, 에이전트가 특정 지각(percepts) 시퀀스를 받은 후 어떤 **행동(action)**을 하는지에 대해 다뤘음
예를 들어, “문이 보이면 문을 연다”
그런데 에이전트의 내부가 어떻게 작동되는지, 어떻게 설계되고 만들어지는지에 대해 알아보겠음
인공지능(AI)의 주요 역할은 **에이전트 프로그램(agent program)**을 설계하는 것
이 프로그램은 **에이전트 함수(agent function)**을 구현하는데, 에이전트 함수란 쉽게 말해 지각을 행동으로 연결하는 규칙
예를 들어, “빨간 불을 보면 멈춘다” 처럼 지각(빨간 불)을 행동(멈춤)으로 바꾸는 과정을 프로그램으로 만든다
이 에이전트 프로그램은 물리적인 sensor(ex: 카메라, 마이크)와 actuator(ex: 바퀴, 팔)을 가진 어떤 컴퓨팅 장치에서 실행됨
우리는 이 장치를 에이전트 아키텍쳐(agent architecture) 라고 부름
-> $agent = architecture + program$
Agent programs#
에이전트 프로그램들의 기본 구조(skeleton)은 센서로부터 현재의 지각(percept)을 입력으로 받아 액츄에이터로 동작(action)을 반환함
여기서 중요한 차이점은 에이전트 프로그램은 현재의 지각만을 입력으로 받는 반면, 에이전트 함수는 전체 지각 이력(percept history)에 의존할 수 있다는 점
에이전트 프로그램은 환경에서 더 많은 정보를 얻을 수 없기 때문에 현재의 지각만 입력으로 사용할 수 밖에 없음
만약 에이전트의 동작이 지각 시퀀스(percept sequence)에 의존해야 한다면, 에이전트는 과거의 지각들을 입력해야 함
Limit of table-driven approach#
테이블 기반 접근 방식이 에이전트 설계에서 실패할 수 없는 이유를 보면
가능한 지각의 집합을 $P$라고 하고, 에이전트의 수명(lifetime, 받을 지각의 총 수)를 $T$라고 하면
조회 테이블(lookup table)은 $\sum_{t=1}^{T} |P|^t$개의 항목을 포함하게 됨
예를 들어, 자율주행 택시를 생각해보면, 단일 카메라(보통 8개 사용)로부터 시각적 입력은 초당 약 70mb(30 fram per sec, 1080x720)의 속도로 들어옴. 이는 1시간 운전 시 $10^{600,000,000,000}$ 이상의 항목을 가진 조회 테이블을 만듦 (관측 가능한 우주의 원자 수는 $10^{80}$미만)
이걸로 알 수 있는 건
- no physical agent in this universe will have the space to store the table
이 우주의 어떤 물리적 에이전트도 테이블을 저장할 공간이 없음
- the designer would not have time to create the table
설계자가 테이블을 만들 시간이 없음
- no agent could ever learn all the right table entries from its experience
어떤 에이전트도 경험을 통해 모든 올바른 테이블 항목을 학습할 수 없음
Key challenge for AI#
The key challenge for AI is to find out how to write programs that, to the extent possible, produce rational behavior from a smallish program rather than from a vast table.
AI의 주요 과제는 방대한 테이블이 아니라 작은 프로그램으로부터 가능한 한 합리적인 행동을 생성하는 방법을 찾는 것
- 단순 반사 에이전트(Simple reflex agents): 현재 지각에만 기반에 즉각적으로 반응함
- 모델 기반 반사 에이전트(Model-based reflex agents): 내부 모델을 활용해 환경을 이해하고 반응함
- 목표 기반 에이전트(Goal-based agents): 특정 목표를 달성하기 위해 동작을 결정함
- 유틸리티 기반 에이전트(Utility-based agents): 최적의 결과를 얻기 위해 유틸리티를 기준으로 동작을 선택함
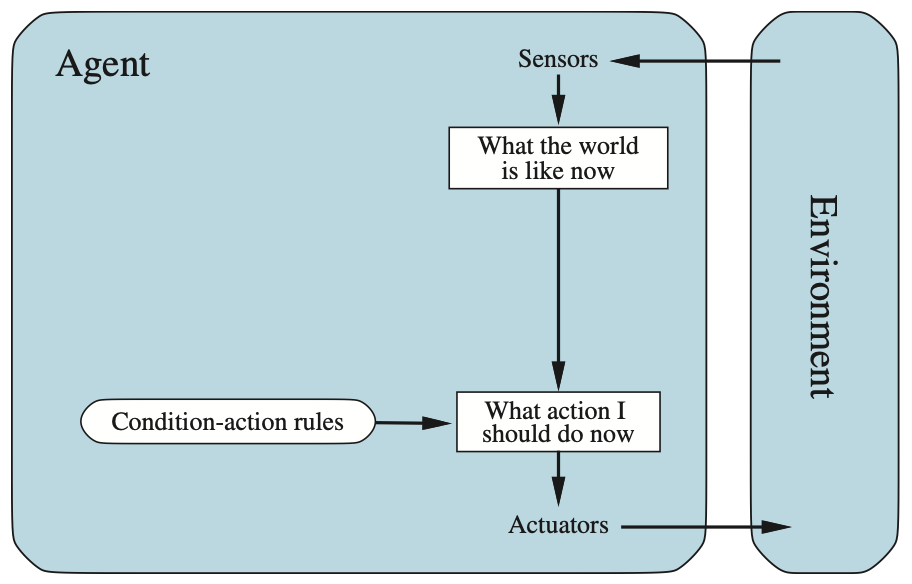
Simple reflex agents#
가장 간단한 형태의 에이전트는 단순 반사 에이전트(Simple Reflex Agent)
이 에이전트는 과거의 지각 이력(percept history)을 무시하고, 오직 현재의 지각(current percept)만을 기반으로 동작을 선택함
예를 들면, 자율주행 택시의 운전을 생각하면, 앞 차가 브레이크를 밟아 브레이크등이 켜지면 이를 인지하고 즉시 브레이크를 밟기 시작해야 함
즉, 시각적 입력을 처리해 “앞차가 브레이킹 중이다"라는 조건을 설정하고, 이 조건이 에이전트 프로그램 내에서 “브레이킹 시작"이라는 동작을 유발함
이런 연결을 **조건-동작 규칙(condition-action rule)**이라고 함
if car-in-front-is-braking then initiate-braking
이렇게 작성함
pros and cons of Simple reflex agent
단순 반사 에이전트는 단순하다는 훌륭한 장점을 가지지만, 기능은 제한적임
이 에이전트는 환경이 **완전히 관찰 가능(fully observable)**한 경우에만 제대로 작동함
약간의 **비관찰 가능성(unobservability)**조차 큰 문제를 일으킬 수 있음
예를 들어 브레이크 예시에서는 앞차의 브레이크 등 구성이 달라 이미지로 브레이킹 여부를 확인할 수 없으면 단순 반사 에이전트는 브레이크를 계속 밟거나, 더 나쁘면 브레이크를 아예 밟지 않을 수도 있음
진공 청소기 문제 (설명은 링크 참고) 에서도 무한 루프에 빠질 수 있음
Solve problem with randomization
무한 루프에서 벗어나는 방법은 에이전트가 동작을 **무작위화(randomization)**하는 것
예를 들어, [Clean]을 지각했을 때 동전을 던져 Right와 Left중 하나를 선택하면 평균적으로 두 단계 내에 다른 칸에 도달하며, 그 칸이 더러우면 청소하고 작업이 완료 됨
따라서 **무작위화된 반사 에이전트(randomization simple reflex agent)**는 결정론적 에이전트보다 더 나은 성능을 낼 수 있음
Rationality of randomization
일부 다중 에이전트 환경(multiagent environment)에서는 적절한 무작위화가 합리적일 수 있음
하지만 단일 에이전트 환경에서는 일반적으로 비합리적임. 무작위화는 단순 반사 에이전트에 유용한 트릭이지만, 대부분의 경우 더 정교한 **결정론적 에이전트(deterministic agent)**가 훨씬 나은 성능을 발휘함
나머지는 2편에 계속…