The Structure of Agents (2)
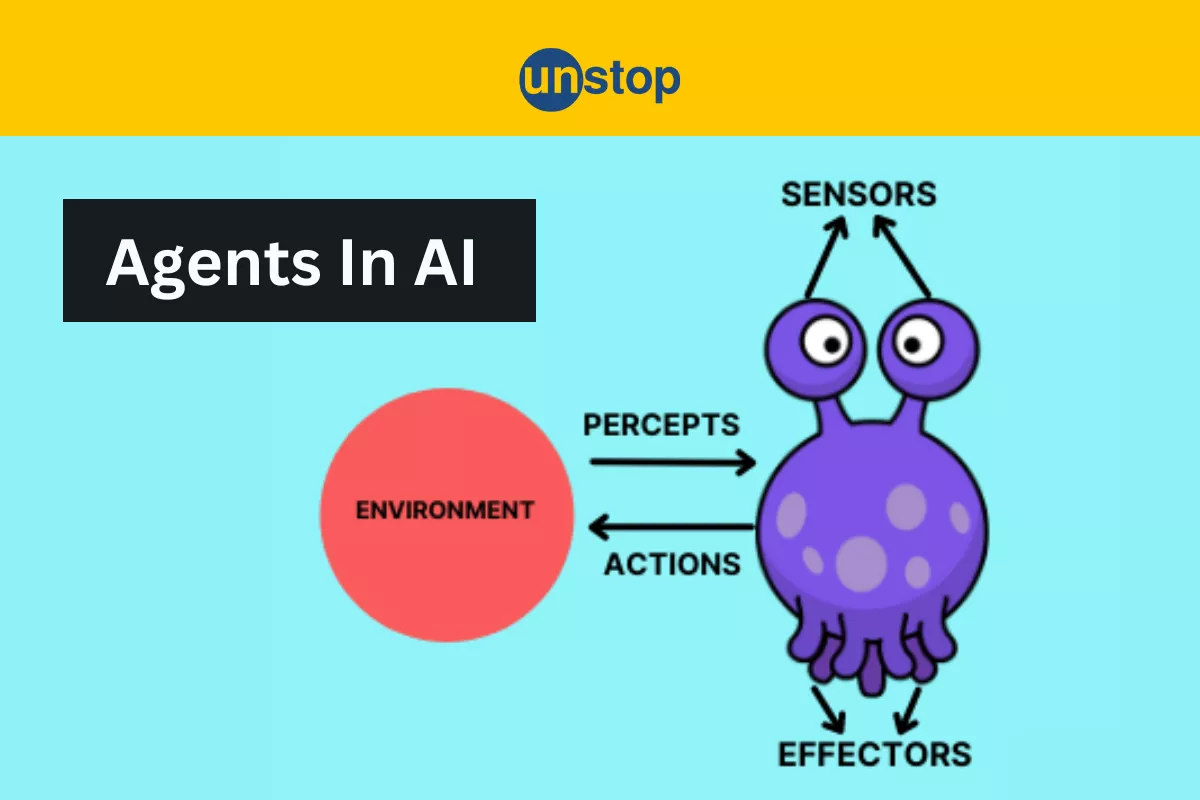
이 사진 아닌 것 같긴 한데 구글에 the structure of agents 치면 나오길래…
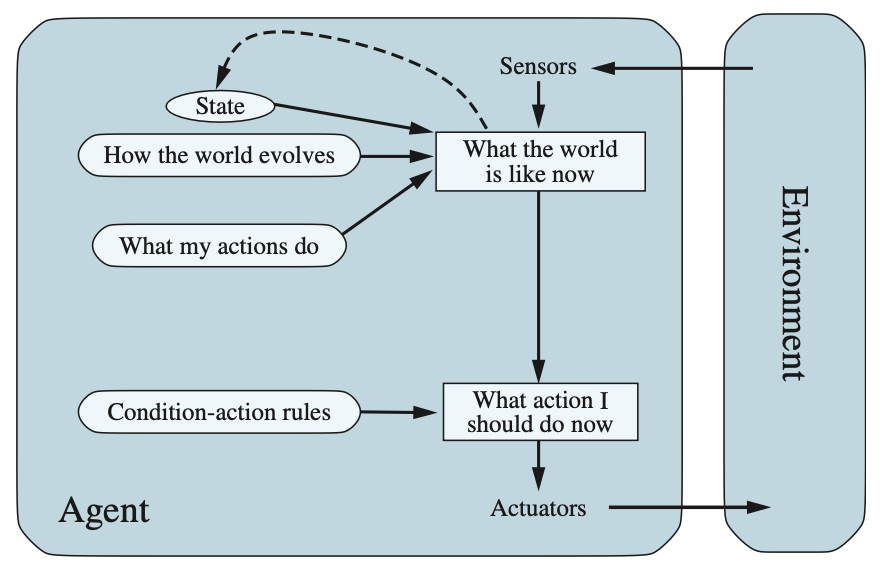
Model-based reflex agents#
부분 관찰 가능성(partial observability)을 다루는 가장 효과적인 방법은 에이전트가 현재 볼 수 없는 세계의 부분을 추적하는 것
즉, 에이전트는 지각 이력(percept history)에 의존하는 일종의 **내부 상태(internal state)**를 유지해야 하며, 이를 통해 현재 상태에서 관찰되지 않는 측면을 어느정도 반영할 수 있어야 함
Knowledge required to update internal state
- 세계가 어떻게 변하는지에 대한 정보
- 에이전트의 행동이 미치는 영향: 핸들을 시계 방향으로 돌리면 차가 오른쪽으로 회전함
- 에이전트와 무관하게 세계가 어떻게 진화하는지: 비가 오면 카메라가 젖을 수 있음
- **전이 모델(transition model)**이라고 불리며, 간단한 불리언 회로(boolean circuits)나 완전한 과학 이론으로 구현될 수 있음
- 세계의 상태가 에이전트의 지각에 어떻게 반영되는지에 대한 정보
- 예를 들어, 앞차가 제동을 시작하면 전방 카메라 이미지에 하나 이상의 빨간 영역이 나타남
- 카메라 젖으면 이미지에 물방울 모양의 물체가 나타나 도로를 부분적으로 가림
- **센서 모델(sensor model)**이라고 불림
Role of Model-based agent
**전이 모델(transition model)**과 **센서 모델(sensor model)**을 결합하면, 에이전트는 세계의 상태를 추적할 수 있음
물론 에이전트의 센서가 가진 한계 때문에 완벽하게 추적하는 것은 어려움
이런 모델을 사용하는 에이전트를 **모델 기반 에이전트(model-based agent)**라고 함
Structure of Model-based agent
위 이미지를 참고하면 현재 지각(percept)이 이전 내부 상태와 결합되어, 세계가 어떻게 작동하는지에 대한 에이전트의 모델을 기반으로 현재 상태의 업데이트 된 설명을 생성하는 과정을 나타냄
Unavoidable of uncertainty
사용되는 표현 방식과 관계없이, 에이전트가 부분적으로 관찰 가능한 환경의 현재 상태를 정확히 파악하는 거의 불가능함
위 이미지에서 “세계가 지금 어떤 상태인지"를 나타내는 상자는 에이전트의 “최선의 추측”(또는 여러 가능성을 고려할 경우 “최선의 추측들)을 나타냄
예를 들어, 자율주행 택시는 앞에 멈춘 큰 트럭 주위를 볼 수 없기 때문에 무엇이 지체를 일으키는지 추측할 수밖에 없음
따라서 현재 상태에 대한 불확실성은 불가피할 수 있지만, 에이전트는 여전히 결정을 내려야 함
Goal-based agents#
환경의 현재 상태에 대해 뭔가를 아는 것만으로는 무엇을 해야 할지 결정하기에 충분하지 않음
택시는 교차로에서 좌회전, 우회전, 직진을 할 수 있음
올바른 결정은 택시가 어디로 가려고 하는지에 달려 있음
즉, 에이전트는 현재 상태 설명 뿐만 아니라 바람직한 상황을 설명하는 일종의 목표(goal) 정보가 필요함
Complexity of goal-based agent
단일 행동으로 즉시 목표를 만족시키는 경우에는 목표 기반 행동 선택이 간단함
하지만 때로는 더 복잡할 수도 있음
예를 들어, 에이전트가 목표를 달성하기 위해 긴 회전과 방향 전환의 시퀀스를 고려해야 하는 경우에는 더 어려움
Feature of goal-based agent
이런 종류의 의사 결정은 조건-행동 규칙과 근복적으로 다름
왜냐하면 “내가 이렇게 하면 무슨 일이 일어날까"와 “그것이 나를 행복하게 할까"와 같은 미래에 대한 고려가 포함되기 때문
반사 에이전트 설계에서는 이 정보가 명시적으로 표현되지 않음
내장된 규칙이 지각에서 행동으로 직접 매핑되기 때문
반사 에이전트는 브레이크등을 보면 브레이크를 밟음 (이유를 알지 못함)
목표 기반 에이전트는 브레이크등을 보면 브레이크를 밟음
왜냐하면 그것이 다른 차와 충돌하지 않겠다는 목표를 달성할 것으로 예측되는 행동이기 때문
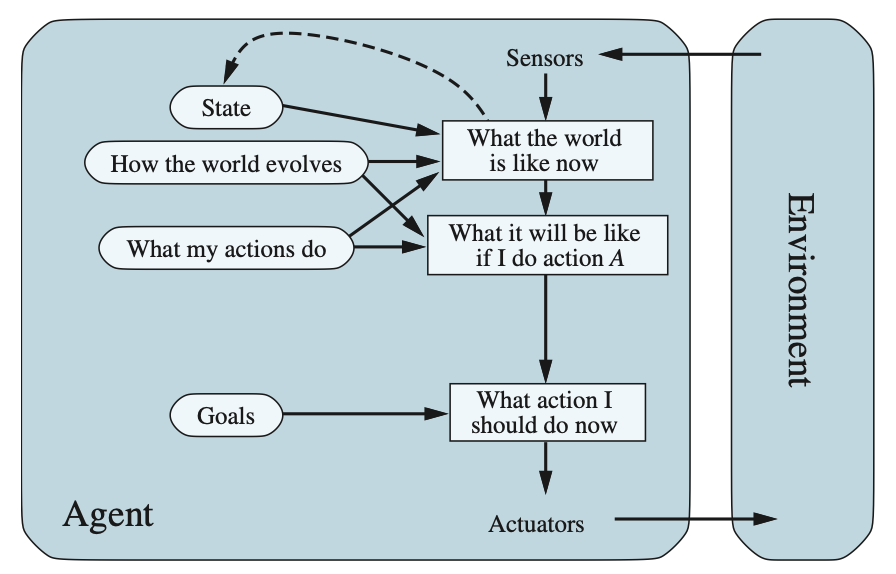
Flexibility of goal-based agents
목표 기반 에이전트는 덜 효율적으로 보일 수 있지만, 의사 결정을 지원하는 지식이 명시적으로 표현되어 수정할 수 있기 때문에 더 유연함
예를 들면, 목표 기반 에이전트의 행동은 단순히 다른 목적지를 목표로 지정함으로써 쉽게 변경할 수 있음
반사 에이전트의 경우, 언제 회전하고 언제 직진할지에 대한 규칙은 단일 목적지에만 작동하며, 새로운 곳으로 가려면 모든 규칙을 교체해야 함
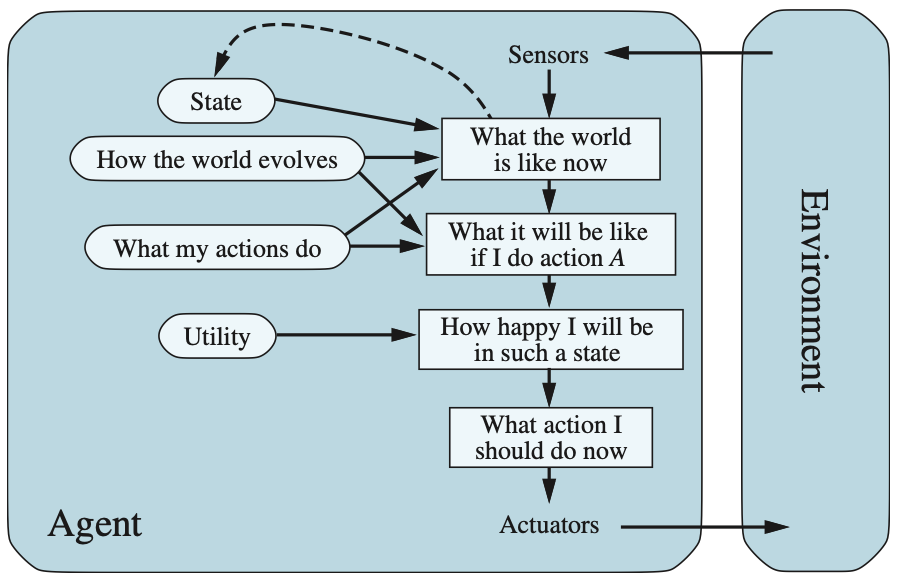
Utility-based agents#
**목표(goals)**만으로는 대부분의 환경에서 고품질의 행동을 생성하기에 충분하지 않음
예를 들어, 많은 행동 시퀀스가 택시를 목적지로 데려다 줄 수 있지만(목표를 달성함), 어떤건 더 빠르고, 안전하며, 신뢰할 수 있거나, 저렴함
목표는 단지 “행복한” 상태와 “불행한” 상태 사이의 조잡한 이진 구분을 제공할 뿐
더 일반적인 **성능 측정(performance measure)**은 에이전트가 얼마나 행복해질지에 따라 서로 다른 세계 상태를 비교할 수 잇어야 함
“행복"이라는 용어가 과학적으로 들리지 않기 때문에 똑똑하신분들이 **유틸리티(utility)**라는 용어를 사용하기로 했다고 함
Performance measurement and utility functions
우리는 이미 성능 측정이 주어진 환경 상태 시퀀스(environment states sequence)에 점수를 할당하여 택시의 목적지에 도달하는 더 바람직한 방법과 덜 바람직한 방법을 쉽게 구분할 수 있다는 것을 봤음
에이전트의 **유틸리티 함수(utility function)**은 본질적으로 성능 측정의 내재화
내부 유틸리티 함수와 외부 성능 측정이 일치한다면, 유틸리티를 최대화하기 위해 행동을 선택하는 에이전트는 외부 성능 측정에 따라 합리적일 것임
하지만 이것이 합리적일 수 있는 유일한 방법은 아님, 진공 청소기 문제에서 rational agent program은 자신의 유틸리티 함수가 무엇인지 전혀 모르는데도 합리적임
하지만 목표 기반 에이전트와 마찬가지로, 유틸리티 기반 에이전트는 유연성(flexibility)와 학습(learning) 측면에서 많은 장점을 가짐
Cases utility > goal
- 상충되는 목표(conflicting goals)
- 달성할 수 있는 목표가 일부에 그칠 때 (ex: 속도와 안전) utility function은 적절한 절충안(tradeoff)를 지정함
- 불확실한 다중 목표
- 에이전트가 추구할 수 있는 여러 목표가 있지만, 그중 어떤 것도 확실히 달성할 수 없을 때, utility는 성공 가능성(likelihood of success)을 목표의 중요성(importance of goals)와 비교해 가중치를 부여함
Decision making under uncertainty
현실 세계에서는 부분 관찰 가능성(partial observability)와 비결정론(nondeterminism)이 흔하며, 따라서 불확실성 하에서의 의사 결정(decision making under uncertainty)도 흔함
기술적으로 말하면 rational utility-based agent는 행동 결과(action outcomes)의 기대 효용(expected utility)을 극대화 하는 행동을 선택함
즉, 각 결과의 확률과 utility를 고려해 평균적으로 기대되는 utility를 계산함
명시적인 utility function을 가진 에이전트는 극대화하려는 특정 utility function에 의존하지 않는 **범용 알고리즘(general-purpose algorithm)**으로 합리적인 결정을 내릴 수 있음
이를 통해 합리성의 “전역적(global)” 정의(최고 성능을 가진 에이전트 함수를 rational로 간주하는 것)가 간단한 프로그램으로 표현 가능한 “지역적(local)“제약으로 변함
이쯤에서 이렇게 질문할 수 있음:
“Is it that simple? We just build agents that maximize expected utility, and we’re done?”
이게 그렇게 간단한가? 기대 효용을 극대화 하는 에이전트를 만들면 끝인가?
이런 에이전트가 지능적(intelligent)일 것이라는 점은 맞음. 하지만 간단하지 않음
utility-based agent는 환경을 모델링하고 추적해야 하며, 이는 **지각(perception), 표현(representation), 추론(reasoning), 학습(learning)**에 대한 많은 연구를 필요로 함
utility를 극대화 하는 행동 과정을 선택하는 것도 어려운 과제이며, 이를 위해 많은 독창적인 알고리즘(ingenious algorithms)이 필요함
그렇게 해도 계산 복잡성(computational complexity)때문에 실제로 완벽한 rationality를 달성하기는 어려움