같은 20토큰, 다른 우주
두 문장을 보자.
“혁명이 숙적을 주인으로 만들지 않는다면 그것만으로도 행운이다” — 야코프 부르크하르트
“오늘 아침에 일찍 일어나서 따뜻한 물로 세수를 하고 밥을 먹은 다음에 학교에 갔다”
토큰 수는 비슷하다. 하지만 첫 번째 문장을 초등학생이 이해할 수 있게 풀어쓰면 7배 넘게 길어진다. 두 번째는 거의 안 늘어난다.
이 차이를 나는 밀도라고 부른다. 같은 그릇에 담긴 내용물의 양이 다른 것. 어렵거나 전문적인 용어를 쓴 게 아니다 — “양자역학적 비국소성 현상”은 어렵지만 명제 하나뿐이다. 밀도가 높은 건 아니다. 밀도는 압축이다.
그래서 궁금했다: 트랜스포머 모델은 이 차이를 “느끼는가?”
PER: 풀어쓰면 몇 배?
기존에 텍스트의 복잡도를 재는 방법은 많다. 퍼플렉서티(perplexity)는 모델이 다음 토큰을 얼마나 잘 예측하는지를 본다. 하지만 이건 “어려운 단어”와 “밀도 높은 의미”를 구분하지 못한다.
나는 새로운 측정법을 하나 만들었다: PER (Paraphrase Expansion Ratio).
방법은 간단하다. LLM에게 원문을 “초등학생이 이해할 수 있게 모든 암묵적 내용을 명시적으로 풀어써”라고 시킨다. 그리고 비율을 잰다.
$$\text{PER}(s) = \frac{|\text{tokens}(\text{paraphrase}(s))|}{|\text{tokens}(s)|}$$
문장 $s$에 대해, LLM이 생성한 풀어쓴 버전의 토큰 수를 원문 토큰 수로 나눈 것이다. PER > 1이면 풀어쓰면 길어진다는 뜻이고, 값이 클수록 원문이 더 압축되어 있다.
부르크하르트 문장: PER = 7.70. 일상 문장: PER = 1.70. 같은 토큰 수인데 정보량이 4.5배 다르다.
기존 측정법과의 차이를 명확히 하자:
| 측정법 | 정의 | 한계 |
|---|---|---|
| Perplexity | $\text{PPL} = \exp!\bigl(-\frac{1}{N}\sum_{i=1}^{N}\log P(t_i \mid t_{<i})\bigr)$ | 어려운 어휘도 높게 나옴 — 밀도와 난이도를 구분 못 함 |
| Propositional Density | 동사/형용사/접속사 수 / 전체 단어 수 | 구조적 측정 — 암묵적 명제를 놓침 |
| PER | $|\text{tokens}(\text{paraphrase})| / |\text{tokens}(\text{original})|$ | 의미론적 측정 — “완전히 이해하려면 얼마나 많은 말이 필요한가” |
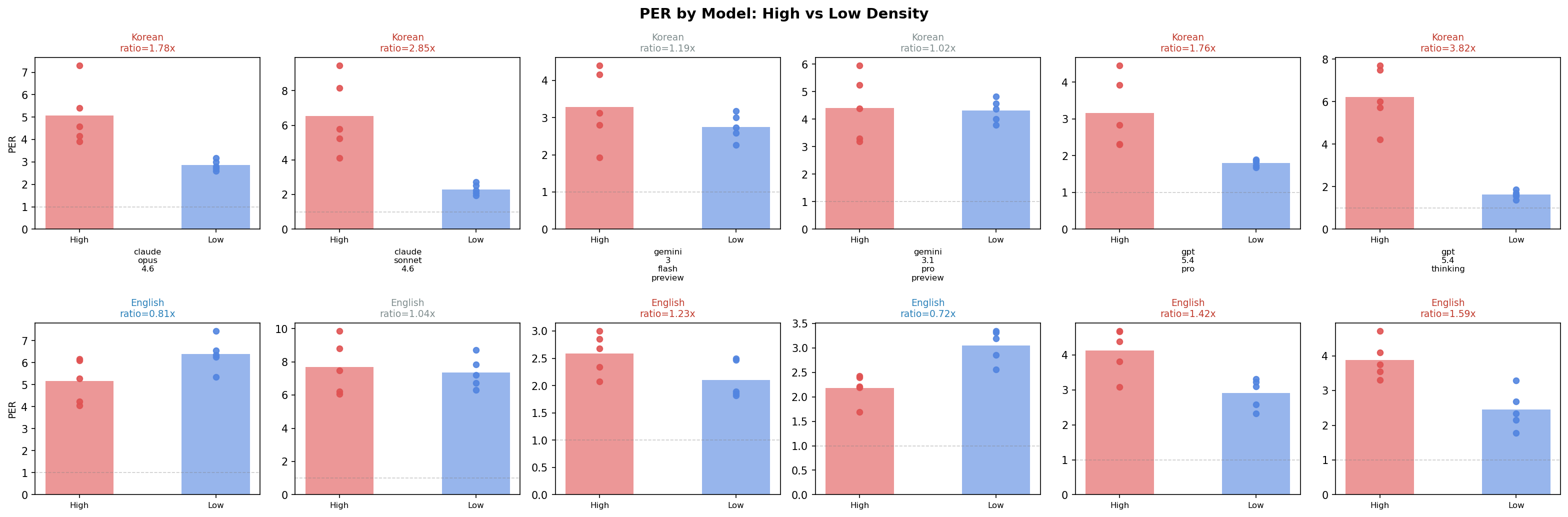 Figure 1: 6개 LLM의 모델별 PER 비교. 한국어 고밀도 문장(빨간색)이 가장 높은 PER을 보인다.
Figure 1: 6개 LLM의 모델별 PER 비교. 한국어 고밀도 문장(빨간색)이 가장 높은 PER을 보인다.
하지만 PER을 재는 도구가 LLM이라면 — LLM마다 다르게 측정하지 않을까?
6개 LLM에게 같은 문장을 풀어쓰게 했다
Claude Opus, Claude Sonnet, GPT-5.4-pro, GPT-5.4-thinking, Gemini Flash, Gemini 3.1 Pro.
한국어 고밀도 5문장, 저밀도 5문장. 영어 동일. 총 20문장.
결과: 두 개의 클러스터가 나타났다.
| 클러스터 | 모델 | 상호 Spearman ρ |
|---|---|---|
| GPT + Claude | 4개 모델 | 0.74 ~ 0.88 *** |
| Gemini | 2개 모델 | 0.54 * |
| 클러스터 간 | — | -0.14 ~ 0.19 (ns) |
GPT와 Claude는 “어떤 문장이 더 dense한지” 서로 동의한다. 하지만 Gemini는 완전히 다른 순위를 매긴다.
LLM 자체가 밀도 측정 도구인데, LLM마다 밀도를 다르게 정의하는 것이다. 이건 오류가 아니라 — “밀도”라는 개념 자체가 해석자에 따라 달라질 수 있다는 것을 보여준다.
재미있는 건 한국어 고밀도 문장이 가장 안정적이었다는 점이다. 어떤 모델을 써도 “이건 확실히 dense하다”고 동의한 문장 상위 5개가 전부 한국어였다 (CV = 0.27~0.28). 영어는 “저밀도”라고 골랐던 문장들이 생각보다 내용이 많아서 모델 간 합의가 안 됐다.
그래서 최종 PER 값은 GPT+Claude 4개 모델의 median-rank ensemble로 산출했다. 절대값이 아닌 순위 기반이기 때문에 개별 모델의 편향에 덜 민감하다.
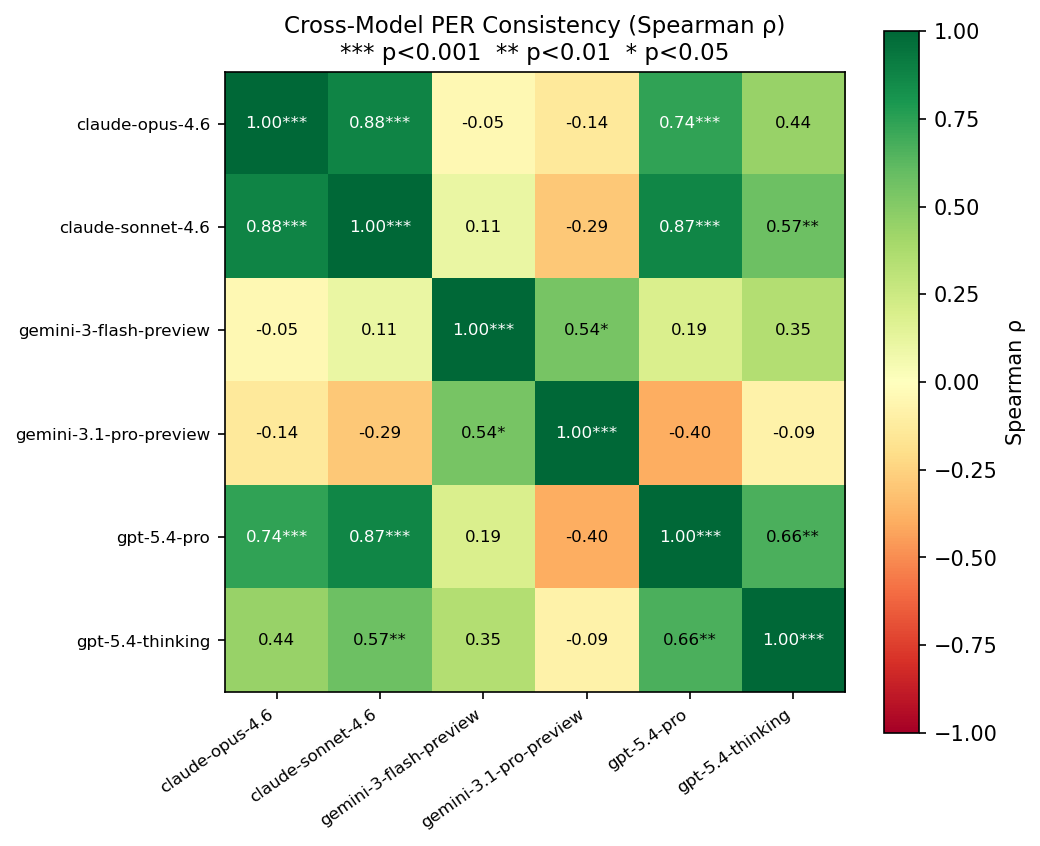 Figure 2: 모델 간 PER 순위 Spearman 상관 행렬. GPT+Claude 클러스터와 Gemini 클러스터가 분리된다.
Figure 2: 모델 간 PER 순위 Spearman 상관 행렬. GPT+Claude 클러스터와 Gemini 클러스터가 분리된다.
모델 안쪽은 무슨 일이 벌어지는가
PER이 밀도를 측정한다고 치자. 그러면 다음 질문: 트랜스포머가 이 문장들을 처리할 때, 내부적으로 뭔가 다른 일이 벌어지는가?
5개 신호를 측정했다. 각각의 수학적 정의는 다음과 같다.
1. Attention Entropy — head $h$, layer $l$에서 query position $i$의 attention 분포 $\mathbf{a}$에 대해:
$$H(\mathbf{a}{l,h,i}) = -\sum{j=1}^{S} a_{l,h,i,j} \log_2 a_{l,h,i,j}$$
높은 entropy = attention이 많은 토큰에 분산. 문장 수준 값은 head와 position에 대해 평균.
2. Hidden State Norm — layer $l$의 hidden state $\mathbf{h}_l \in \mathbb{R}^{S \times D}$에 대해:
$$|\mathbf{h}l| = \frac{1}{S}\sum{i=1}^{S} |\mathbf{h}_{l,i}|_2$$
3. Layer Delta — 연속된 레이어 간 표현 변화량:
$$\delta_l = 1 - \frac{\bar{\mathbf{h}}l \cdot \bar{\mathbf{h}}{l-1}}{|\bar{\mathbf{h}}l| |\bar{\mathbf{h}}{l-1}|}$$
여기서 $\bar{\mathbf{h}}_l$는 토큰 차원에 대한 mean pooling. $\delta_l = 0$이면 두 레이어의 표현이 동일, $\delta_l = 1$이면 직교.
4. Effective Rank — hidden state의 SVD $\mathbf{h}_l = U \Sigma V^T$에서 singular values $\sigma_1, \ldots, \sigma_k$를 정규화한 확률 분포 $p_i = \sigma_i / \sum_j \sigma_j$로:
$$\text{erank}(\mathbf{h}l) = \exp!\Bigl(-\sum{i} p_i \log p_i\Bigr)$$
Shannon entropy의 지수 — 표현이 몇 개의 “유효한” 차원을 사용하는지를 측정.
5. Attention Distance — attention-weighted position distance:
$$d_{l,h,i} = \sum_{j=1}^{S} a_{l,h,i,j} \cdot |i - j|$$
먼 토큰에 attention이 갈수록 높은 값. 장거리 의존성의 지표.
4개 모델로 실험했다:
klue/bert-base— 한국어 전용 encoderbert-base-uncased— 영어 전용 encodergpt2— 영어 decoder (baseline)Qwen3-0.6B— 한/영 multilingual modern decoder
파일럿: 첫 번째 실험 (n=5)
첫 번째 교훈: 실패가 더 많은 걸 가르쳐준다
사실 처음에는 mBERT(다국어 BERT)와 GPT-2로 실험했다. 결과: 아무것도 안 나왔다. 5개 신호, 2개 모델, 전부 p > 0.05.
왜 안 보였을까? GPT-2는 영어 전용인데 한국어 문장도 넣었다. GPT-2한테 “혁명이 숙적을 주인으로…”는 의미 없는 바이트 시퀀스일 뿐이다.
모델을 바꾸니 모든 게 달라졌다. 한국어를 아는 모델(klue/bert-base)을 쓰자 신호가 나타났다.
이건 사소해 보이지만 중요한 교훈이다. 모델이 해당 언어를 “이해”하지 못하면, 밀도 차이는 내부 신호에 반영되지 않는다. 의미를 처리하는 모델이어야 의미의 밀도 차이가 보이는 것이다.
Layer Delta — 유일한 유의미 신호
klue/bert-base (한국어)
Layer Delta High > Low p = 0.032 *
(나머지 4개 신호: 전부 ns)고밀도 문장에서 레이어 사이의 표현 변화가 더 크다. 직관적으로 맞다: 압축된 의미를 펼치려면 각 레이어가 더 많은 “일”을 해야 한다.
 Figure 3: klue/bert-base 한국어 문장의 층별 내부 신호 (빨간색=고밀도, 파란색=저밀도).
Figure 3: klue/bert-base 한국어 문장의 층별 내부 신호 (빨간색=고밀도, 파란색=저밀도).
그리고 여기서 재미있는 반전이 나온다.
Encoder와 Decoder는 밀도를 정반대로 처리한다
Qwen3-0.6B(decoder)에서도 Layer Delta 경향이 나타났는데 — 방향이 반대였다.
klue/bert-base (encoder): Layer Delta High > Low p = 0.032 *
Qwen3-0.6B (decoder): Layer Delta High < Low p = 0.076 (marginal)Encoder에서는 고밀도 → 더 큰 변화. Decoder에서는 고밀도 → 오히려 안정적.
같은 문장, 같은 신호인데 모델 구조에 따라 반대. 왜?
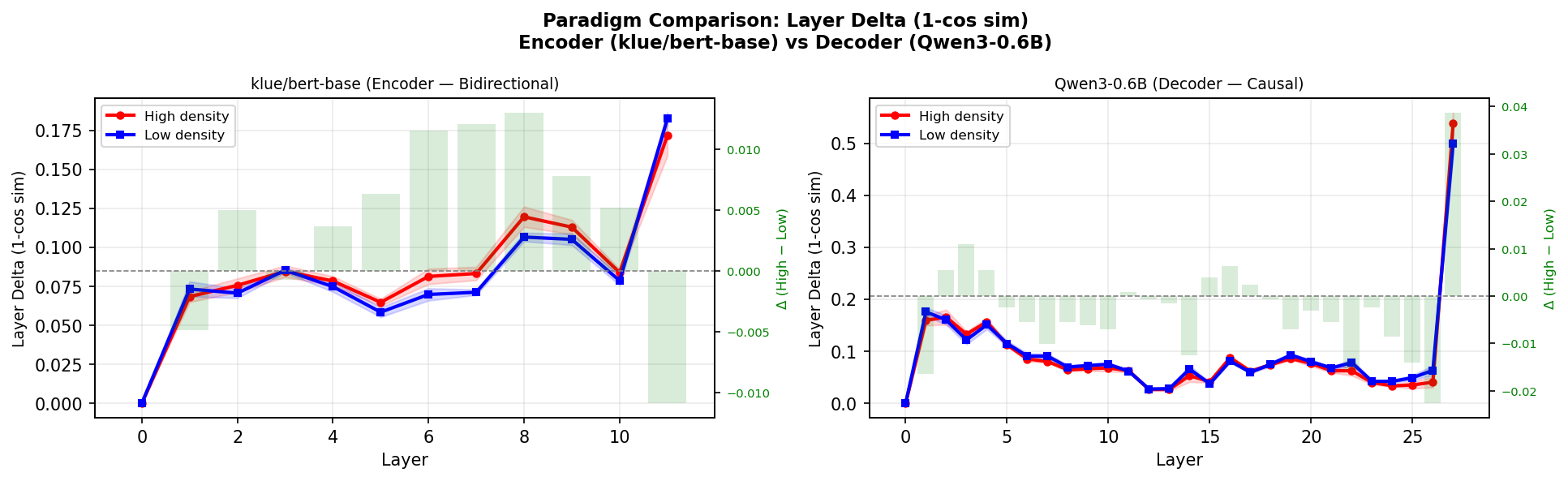 Figure 5: Encoder(klue/bert-base)와 Decoder(Qwen3-0.6B)의 Layer Delta 비교. 방향이 반대임을 보여준다.
Figure 5: Encoder(klue/bert-base)와 Decoder(Qwen3-0.6B)의 Layer Delta 비교. 방향이 반대임을 보여준다.
Surprisal이 답을 준다
Qwen3-0.6B로 토큰별 surprisal을 계산했다. 토큰 $t_i$의 surprisal은:
$$s(t_i) = -\log_2 P(t_i \mid t_1, \ldots, t_{i-1})$$
이것이 Shannon 정보량 — 해당 토큰이 문맥상 얼마나 “놀라운가”를 비트 단위로 측정한 것이다. 문장 수준의 지표로는 평균 surprisal $\bar{s}$와 변동계수(coefficient of variation)를 사용한다:
$$\text{CV}(s) = \frac{\sigma(s)}{\bar{s}}$$
CV가 낮으면 토큰마다 정보량이 균일하고, 높으면 들쭉날쭉하다.
| 지표 | 한국어 | 영어 |
|---|---|---|
| Mean surprisal $\bar{s}$ | High > Low, p=0.032* | High > Low, p=0.008** |
| Surprisal CV | High < Low, p=0.008** | High < Low, ns |
고밀도 문장은 토큰당 정보량이 더 높다 (당연하다). 하지만 핵심은 두 번째 줄이다: 한국어 고밀도 문장은 정보가 토큰들에 더 균일하게 배분되어 있다 (CV = 0.68 vs 0.95).
이것이 UID(Uniform Information Density) 가설 (Levy & Jaeger, 2007)이다. 화자는 단위 시간당 정보 전달률을 채널 용량 근처에서 균일하게 유지하도록 발화를 조절한다:
$$\text{UID}: \quad \text{Var}[s(t_i)] \to \min \quad \text{subject to} \quad \bar{s} \leq C$$
잘 쓰여진 밀도 높은 문장은 정보량을 골고루 분배한다. 들쭉날쭉하지 않다.
이제 decoder의 반대 방향이 설명된다:
- 고밀도 → surprisal이 균일 ($\text{CV} \downarrow$) → 매 토큰에서 비슷한 양의 “놀라움” → 레이어마다 비슷한 $\delta_l$ → $\sum_l \delta_l$ 이 낮음
- 저밀도 → surprisal이 들쭉날쭉 ($\text{CV} \uparrow$) → 특정 토큰에서 큰 놀라움 → 그 지점에서 큰 $\delta_l$ 발생
Encoder는 문장 전체를 동시에 보기 때문에 “총량”이 보인다. Decoder는 토큰을 하나씩 처리하기 때문에 “균일함”이 보인다.
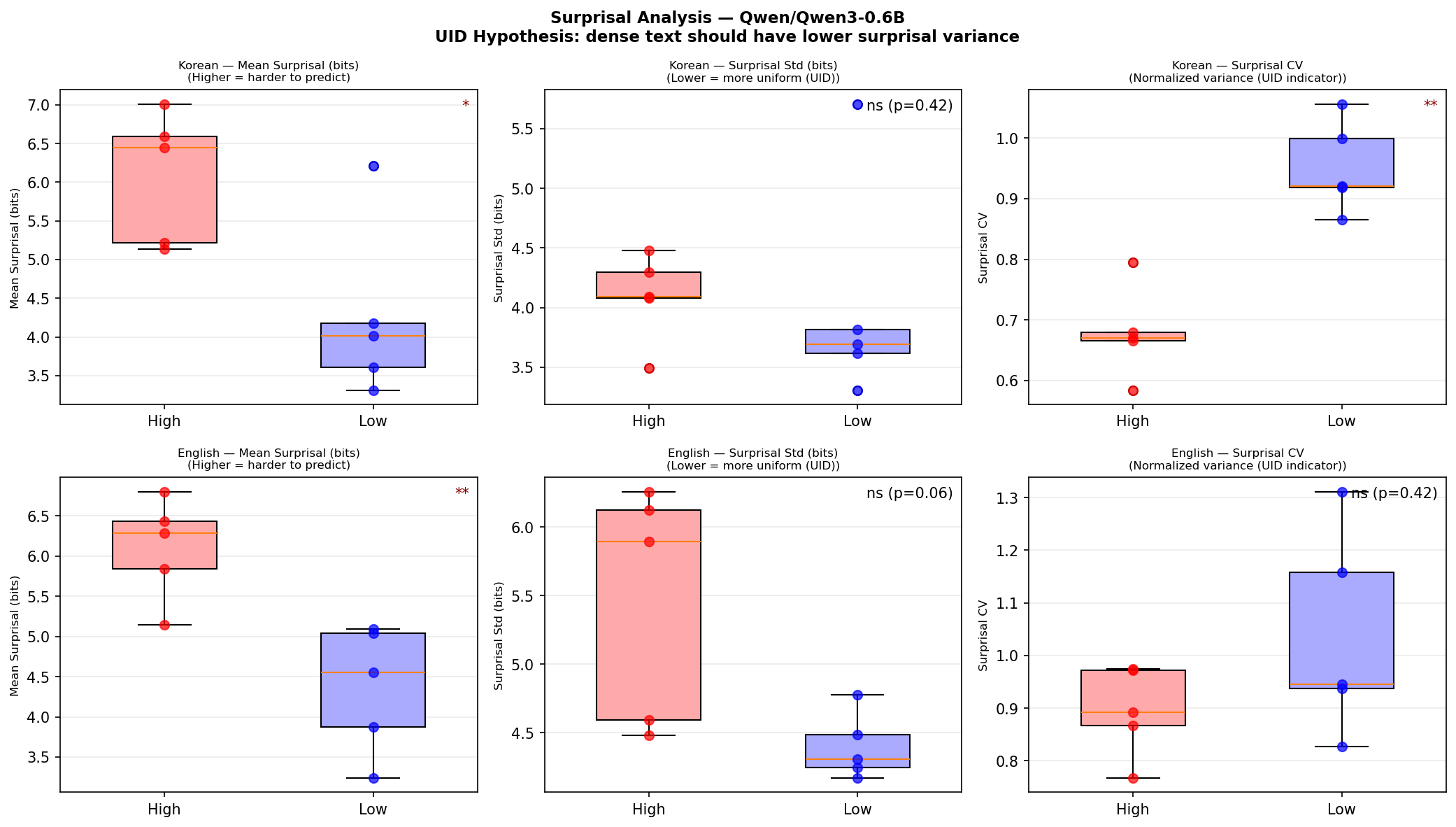 Figure 4: Qwen3-0.6B 기반 surprisal 분석. 한국어 고밀도 문장의 CV가 유의미하게 낮다 (p=0.008*).*
Figure 4: Qwen3-0.6B 기반 surprisal 분석. 한국어 고밀도 문장의 CV가 유의미하게 낮다 (p=0.008*).*
여기까지가 파일럿이다 — 하지만 문제가 있다
파일럿 결과는 흥미롭지만, 솔직히 취약했다. 몇 가지 문제가 있었다.
첫째, 표본 크기가 너무 작다. 고밀도 5문장 vs 저밀도 5문장. 이 표본 크기로 p=0.032를 얻었다는 건, 효과 크기가 엄청 크거나 운이 좋았거나 둘 중 하나다. 영어 Surprisal CV가 n.s.였던 것도 검정력(statistical power) 부족 때문일 수 있다.
둘째, 교락 변수를 통제하지 못했다. 고밀도 문장은 부르크하르트 격언 같은 것들이고, 저밀도 문장은 일상 서술문이다. “밀도”가 아니라 “문체”에 반응하는 것일 수 있다. 격언은 어휘부터 다르니까.
셋째, 영어에서는 Layer Delta가 유의미하지 않았다. 한국어에서만 보인 효과라면, 이게 언어 특성인지 표본 문제인지 알 수 없다.
이 문제들을 해결하기 위해 두 가지 검증 실험을 설계했다.
검증 실험 1: 확대 코퍼스 (n=25/group)
파일럿의 20문장을 100문장으로 확대했다. 한국어 50문장(고밀도 25, 저밀도 25), 영어 50문장(고밀도 25, 저밀도 25).
고밀도 문장은 격언 스타일의 압축된 표현을 유지했지만, 훨씬 더 다양한 주제를 다룬다. “늦은 준비는 빠른 후회를 부른다”, “빈 칭찬은 신뢰를 깎는다”, “작은 누수도 배를 가라앉힌다” 같은 문장들. 저밀도 문장은 동일한 의미를 풀어쓴 일상적 서술문이다: “시험 전날에 공부를 시작하면 모든 내용을 충분히 복습하기 어렵다”, “밤에 쉬는 시간을 줄이면 다음 날 업무 중에 더 쉽게 피곤해진다”.
동일한 모델, 동일한 신호 추출 코드로 Mann-Whitney U test를 수행했다. 결과는 다음과 같다:
| 신호 | 언어 | 방향 | p값 |
|---|---|---|---|
| Layer Delta | KO | H > L | .003** |
| Layer Delta | EN | H > L | .0001*** |
| Surprisal Mean | KO | H > L | <.0001*** |
| Surprisal Mean | EN | H > L | <.0001*** |
| Surprisal CV | KO | H < L | <.0001*** |
| Surprisal CV | EN | H < L | .003** |
파일럿에서 안 보이던 것들이 보이기 시작했다.
영어 Layer Delta가 유의미해졌다 (p=0.0001). 파일럿에서는 n.s.였는데, 단순히 표본이 부족했던 거다. 표본 크기를 5배 늘리자 영어에서도 동일한 패턴이 명확하게 드러났다. 이건 한국어만의 현상이 아니다.
영어 Surprisal CV도 유의미해졌다 (p=0.003). 파일럿에서 한국어만 유의미했던 UID 효과가, 표본을 늘리니 영어에서도 나타났다. 고밀도 문장의 정보 균일 배분은 언어를 초월한 현상이라는 근거가 생겼다.
그리고 한국어 Surprisal CV는 p<0.0001로 더 강해졌다. 파일럿에서 p=0.008이었던 것이 세 자릿수나 떨어졌다. n=5에서 이미 보였던 효과가 n=25에서 더 확고해진 것이다.
한 가지 재미있는 점: 한국어가 영어보다 더 뚜렷하게 밀도 차이를 보인다. Layer Delta는 영어가 더 유의미하지만, Surprisal CV는 한국어가 압도적이다. 이건 한국어의 SOV(주어-목적어-서술어) 구조와 관계가 있을 수 있다. 한국어는 문장 끝에 서술어가 오기 때문에, 밀도 높은 문장에서 정보가 앞쪽 토큰들에 더 고르게 분산될 수 있다.
검증 실험 2: Minimal Pairs (n=50 paired)
확대 코퍼스가 표본 크기 문제를 해결했다면, 교락 변수 문제는 여전히 남아 있다. 고밀도 문장과 저밀도 문장이 근본적으로 다른 종류의 텍스트일 수 있다.
이걸 해결하기 위해 minimal pair 접근을 사용했다. 같은 의미를 담되 압축 수준만 다른 문장 쌍 100개(한국어 50, 영어 50)를 만들었다.
예를 들어:
| 저밀도 (풀어쓴 표현) | 고밀도 (압축 표현) |
|---|---|
| 발표 전에 충분히 준비하지 않으면 질문을 받을 때 제대로 답하기 어렵다 | 준비 없는 발표는 질문 앞에서 흔들린다 |
| 파일을 백업하지 않은 채 시스템을 업데이트하면 중요한 문서를 잃을 수 있다 | 백업 없는 업데이트는 문서 손실을 부른다 |
| 창문에 생긴 작은 금을 그냥 두면 점점 커져서 결국 유리가 깨질 수 있다 | 방치한 금은 결국 유리를 깨뜨린다 |
각 쌍은 의미가 동일하다. 다른 건 구문적 압축 수준뿐이다. 같은 명제를 짧게 말하느냐, 길게 풀어쓰느냐의 차이. 이렇게 하면 “밀도의 효과”와 “주제의 효과”를 분리할 수 있다.
paired test이므로 Wilcoxon signed-rank test를 사용했다. 결과:
| 신호 | 언어 | 방향 | p값 |
|---|---|---|---|
| Layer Delta | KO | H > L | .005** |
| Layer Delta | EN | H > L | <.0001*** |
| Surprisal Mean | KO | H > L | <.0001*** |
| Surprisal Mean | EN | H > L | <.0001*** |
| Surprisal CV | KO | H < L | <.0001*** |
| Surprisal CV | EN | H < L | <.0001*** |
모든 핵심 신호가 재현되었다. 의미를 통제한 상태에서도 동일한 패턴이 나타났다는 것은, 이 효과가 어휘나 문체의 차이가 아니라 텍스트 압축 그 자체에 대한 모델의 반응이라는 뜻이다.
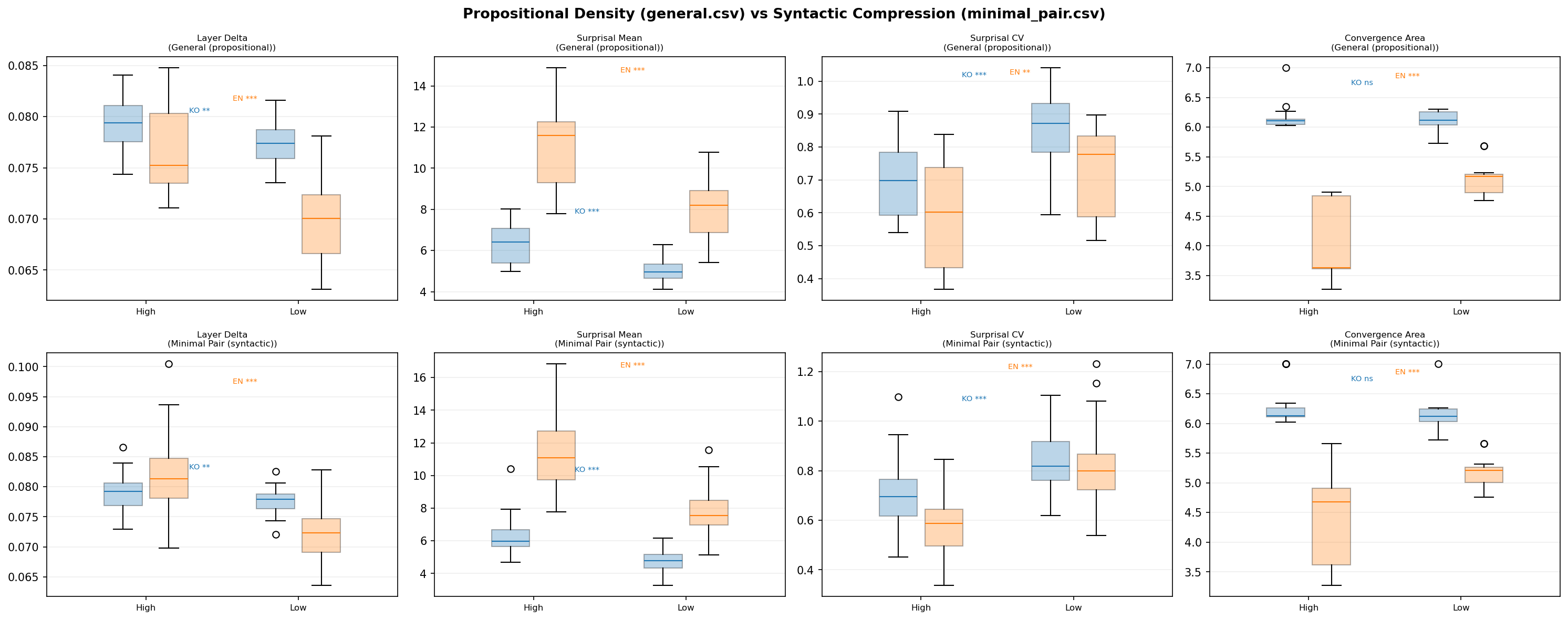 Figure 6: 명제적 밀도(general) vs 구문적 압축(minimal pair) 비교.
Figure 6: 명제적 밀도(general) vs 구문적 압축(minimal pair) 비교.
특히 주목할 점은 영어 Surprisal CV다. 확대 코퍼스에서 p=0.003이었는데, minimal pair에서 p<0.0001로 더 강해졌다. paired test의 검정력이 더 높기도 하지만, 의미를 통제했을 때 오히려 효과가 더 선명해진 것이다. 이건 좋은 징조다 — 교락 변수가 효과를 가리고 있었다는 뜻이니까.
PER이 내부 신호와 직접 연결된다
여기서 한 걸음 더 나아가 봤다. PER이 “밀도를 재는 외부 지표”이고 Layer Delta/Surprisal이 “모델의 내부 반응”이라면, 이 둘이 상관되어야 하지 않을까?
파일럿의 원본 20문장에 대해 PER(GPT+Claude 앙상블)과 내부 신호의 Spearman 상관을 계산했다.
| 상관 | ρ | p |
|---|---|---|
| PER ↔ Surprisal Mean | 0.867 | ** |
| PER ↔ Surprisal CV | -0.952 | <0.0001*** |
ρ = -0.952. PER이 높은 문장일수록 surprisal의 변동계수가 낮다 — 즉, 정보가 더 균일하게 배분된다. 이 상관의 강도는 거의 완벽에 가깝다.
이것은 PER이 단순한 “LLM이 얼마나 길게 풀어쓰는가”를 넘어서, 트랜스포머 내부의 정보 분포 균일성과 직결된 지표라는 것을 의미한다. 외부 측정(PER)과 내부 반응(Surprisal CV)이 독립적으로 같은 것을 가리키고 있다.
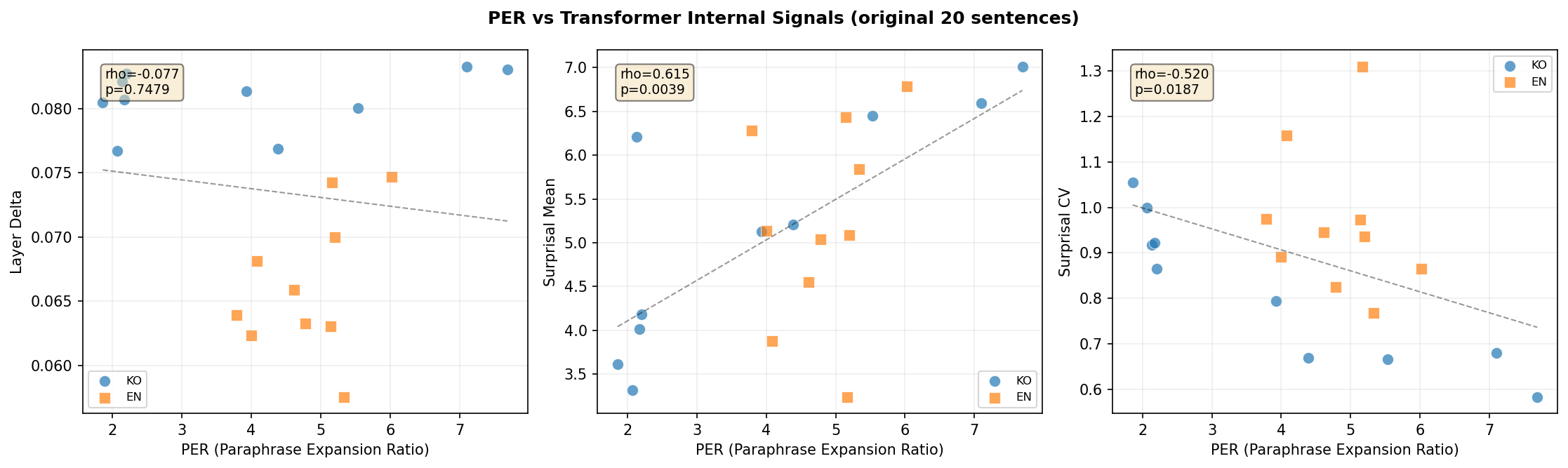 Figure 7: PER과 트랜스포머 내부 신호 간 상관. 한국어에서 PER↔Surprisal CV (ρ=-0.952)의 강한 음의 상관.
Figure 7: PER과 트랜스포머 내부 신호 간 상관. 한국어에서 PER↔Surprisal CV (ρ=-0.952)의 강한 음의 상관.
신호 간 교차 상관: 세 패러다임이 하나의 체계를 이룬다
확대 코퍼스(100문장)에서 신호 간의 교차 상관도 분석했다. Layer Delta(Encoder 신호), Surprisal(Decoder 신호), 그리고 Convergence Area(Diffusion 신호 — Part 2에서 자세히 다룬다)가 서로 독립인지, 아니면 연결되어 있는지 보기 위해서다.
| 교차 상관 | ρ | p | 언어 |
|---|---|---|---|
| Layer Delta ↔ Surprisal Mean | 0.378 | .007** | KO |
| Surprisal Mean ↔ Conv. Area | -0.624 | <.0001*** | EN |
한국어에서 Layer Delta와 Surprisal Mean의 양의 상관 (ρ=0.378)은, Encoder가 “더 많이 변화하는” 문장이 Decoder에서도 “더 놀라운” 문장이라는 것을 뜻한다. 두 패러다임이 같은 밀도 속성에 각자의 방식으로 반응하는 것이다.
영어에서 Surprisal과 Convergence Area의 음의 상관 (ρ=-0.624)은 더 흥미롭다. Decoder가 “놀라운” 문장은 Diffusion에서 복원이 더 어렵다 (convergence area가 크다). 이건 Part 2에서 더 자세히 다루겠지만, 핵심은 이것이다: Encoder, Decoder, Diffusion 세 패러다임의 밀도 반응은 서로 독립이 아니라 하나의 일관된 체계를 이룬다.
함정: 분류는 너무 쉽다
실험 도중에 probing classifier를 돌렸다. 각 레이어의 hidden state로 logistic regression을 훈련시켜서 “이 문장이 고밀도인지 저밀도인지” 분류하게 했다.
결과: 모든 레이어에서 100% 정확도.
처음엔 기뻐했다. 그런데 PCA를 해봤더니 1개 주성분만으로 완벽하게 분리되었다.
이건 밀도를 인코딩하는 게 아니다. 모델은 “격언인가 일상문인가”를 보고 있을 뿐이다. “혁명이 숙적을 주인으로…” 같은 문장과 “오늘 아침에 일찍 일어나서…” 같은 문장은 어휘부터 완전히 다르다. 임베딩 레이어부터 이미 구분된다.
이건 마치 “이 AI는 고양이와 개를 구분합니다!”라고 했는데, 사실 사진의 배경색을 보고 구분하는 것과 같다.
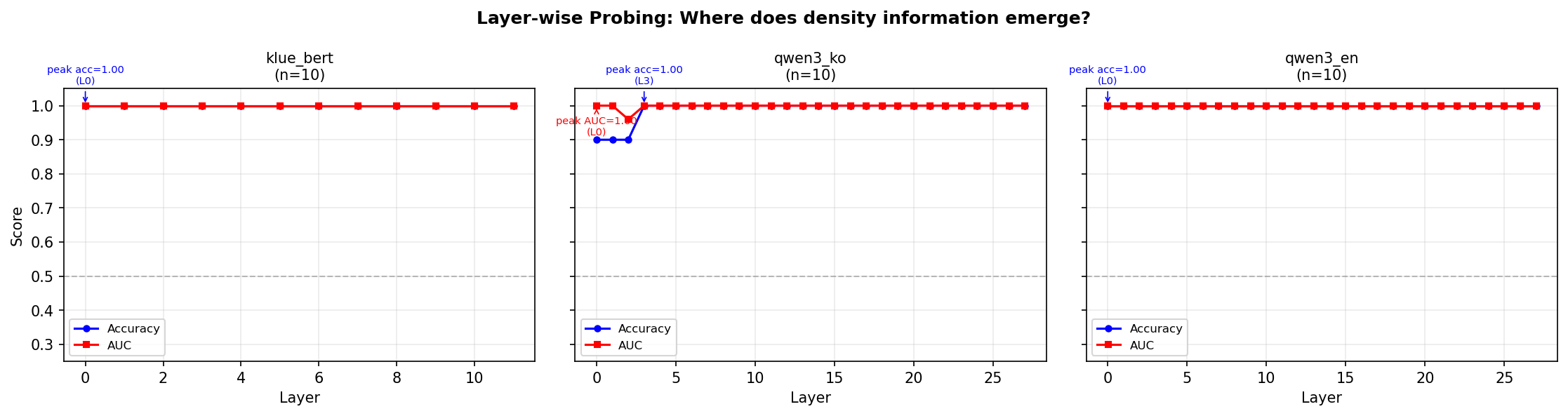 Figure 8: Layer-wise probing classifier 결과. 모든 레이어에서 100% 정확도 — PCA(1)로 분리 가능한 표면 특성.
Figure 8: Layer-wise probing classifier 결과. 모든 레이어에서 100% 정확도 — PCA(1)로 분리 가능한 표면 특성.
진짜 질문은 “분류할 수 있는가?”가 아니라 “어떻게 처리하는가?”다.
Layer Delta와 Surprisal이 답하는 건 바로 이 두 번째 질문이다. 그리고 이 함정을 인식했기 때문에 minimal pair 실험을 설계한 것이다 — 어휘와 문체가 아닌 압축 수준만 다른 문장 쌍을 만들어서, “처리 방식의 차이”가 표면적 특성이 아닌 실제 밀도에 기인하는지 확인하기 위해.
전체 결과 요약
파일럿부터 검증까지의 전체 여정을 표 하나로 정리하자.
| 신호 | 한국어 | 영어 | |||
|---|---|---|---|---|---|
| 확대코퍼스 | Minimal Pair | 확대코퍼스 | Minimal Pair | ||
| Layer Delta | .003** | .005** | .0001*** | <.0001*** | |
| Surprisal CV | <.0001*** | <.0001*** | .003** | <.0001*** |
두 실험, 두 언어, 두 핵심 신호 — 8개 테스트 중 8개 전부 유의미하다. 파일럿에서 불확실했던 영어 결과까지 전부 확인됐다.
정리: 무엇을 알게 되었는가
-
PER은 밀도를 잰다 — 하지만 측정 도구(LLM)에 따라 달라진다. GPT+Claude 앙상블의 median-rank로 안정적인 순위를 얻을 수 있다. 그리고 PER과 Surprisal CV의 상관 ρ=-0.952는 PER이 단순한 외부 지표가 아니라 모델 내부의 정보 분포와 직결됨을 보여준다.
-
모델이 언어를 “이해”해야 밀도가 보인다 — GPT-2에 한국어를 넣으면 안 나오지만, klue/bert-base를 쓰면 Layer Delta가 유의미하다. 이 실패가 연구의 방향을 바꿨다.
-
Encoder와 Decoder는 밀도를 반대 방향으로 처리한다 — Encoder는 고밀도에서 Layer Delta가 크고, Decoder에서는 surprisal이 더 균일하다. 둘 다 “밀도를 느끼고 있다”는 점은 같지만, 보는 관점이 다르다.
-
분류가 쉽다고 인코딩되는 건 아니다 — PCA 1차원으로 100% 분리되면 그건 표면 특성이다. “어떻게 처리하느냐”를 봐야 한다. Minimal pair가 이 구분을 가능하게 했다.
-
UID 가설이 한국어와 영어 모두에서 확인된다 — 고밀도 문장은 정보를 토큰들에 균일하게 배분한다. 파일럿에서는 한국어만 유의미했지만, 검증 실험에서 영어도 p=0.003으로 확인됐다.
-
세 패러다임의 신호는 하나의 밀도 반응 체계를 이룬다 — Layer Delta, Surprisal, Convergence Area가 서로 상관되어 있다. 밀도는 패러다임에 따라 다른 “형태”로 발현되지만, 근원은 하나다.
다음: Part 2 — Diffusion은 밀도를 어떻게 복원하는가
Encoder는 문장 전체를 동시에 본다. Decoder는 왼쪽에서 오른쪽으로 하나씩 처리한다. 그렇다면 Diffusion은? 노이즈에서 텍스트로 복원하는 과정에서, 밀도 높은 문장은 더 어려운가?
확대 코퍼스에서 영어 Convergence Area는 p<0.0001로 강력하게 유의미했다. 그런데 한국어에서는 null이었다. 왜?
Part 2에서는 BERT 기반 D3PM absorbing-state diffusion 근사를 사용한 convergence area 분석, 한국어 SOV 구조가 diffusion 복원 순서에 미치는 영향, 그리고 “밀도가 높으면 결정화(crystallization)가 정말 더 어려운가?”를 다룬다.