이 글은 Part 1: 트랜스포머는 글의 밀도를 느끼는가의 후속편이다.
Part 1에서 우리는 트랜스포머의 forward pass를 관찰했다. Encoder(BERT)에서는 고밀도 문장의 Layer Delta가 더 크고, Decoder(Qwen3)에서는 surprisal이 더 균일하다는 것을 발견했다. 하지만 두 가지 문제가 있었다: 표본이 n=5로 너무 작았고, 고밀도 문장(격언)과 저밀도 문장(일상문)의 문체 자체가 달랐다.
이번에는 두 가지를 한다. 첫째, 관점을 바꾼다 — 문장을 완전히 파괴한 다음, 처음부터 복원해본다. 둘째, 검증한다 — 100문장과 100개의 minimal pair로 Part 1의 발견을 확인한다.
Diffusion Language Model이란
이미지 생성 AI(Stable Diffusion, DALL-E)를 써봤다면 원리를 안다. 노이즈에서 시작해서 점점 깨끗한 이미지를 만들어간다. 텍스트에도 같은 걸 할 수 있다.
Discrete Diffusion (D3PM; Austin et al., 2021)은 이산 상태 공간에서의 확산 과정이다. Absorbing state 변형에서, forward process는 각 토큰을 독립적으로 absorbing state $[\text{MASK}]$로 전이시킨다:
$$q(x_t \mid x_0) = \text{Cat}\bigl(x_t;; (1-\beta_t),\mathbf{e}{x_0} + \beta_t,\mathbf{e}{[\text{MASK}]}\bigr)$$
여기서 $\beta_t$는 noise schedule, $\mathbf{e}$는 one-hot 벡터. $t \to T$이면 모든 토큰이 $[\text{MASK}]$가 된다.
Reverse process는 각 step에서 모델 $p_\theta(x_0 \mid x_t)$를 사용하여 마스킹된 위치의 원래 토큰을 예측한다:
$$p_\theta(x_{t-1} \mid x_t) = \sum_{x_0} q(x_{t-1} \mid x_t, x_0), p_\theta(x_0 \mid x_t)$$
이 과정에서 모델의 확신도(confidence)와 불확실성(entropy)을 매 스텝마다 기록하면, 문장이 “결정화”되는 궤적을 볼 수 있다.
결정화 가설: 밀도 높은 문장은 복원하기 더 어렵다. 더 많은 스텝 동안 불확실성이 높게 유지된다.
BERT를 Diffusion 모델로 쓴다
이상적으로는 MDLM 같은 전용 Diffusion Language Model을 쓰고 싶었다. 하지만 MDLM 코드베이스는 flash_attn과 triton — NVIDIA GPU 전용 라이브러리 — 에 하드코딩되어 있어서 Apple Silicon에서 돌릴 수 없었다. BD3-LM도 같은 사정이었다.
대안: BERT를 discrete diffusion denoiser로 쓴다.
이건 편법이 아니다. Absorbing state D3PM에서 reverse step의 핵심 연산은 $p_\theta(x_0 \mid x_t)$ — 마스킹된 토큰의 원래 값을 예측하는 것이다. 이것이 정확히 BERT의 Masked Language Modeling objective:
$$\mathcal{L}{\text{MLM}} = -\mathbb{E}{i \in \mathcal{M}} \bigl[\log P_\theta(x_i \mid \mathbf{x}_{\backslash \mathcal{M}})\bigr]$$
여기서 $\mathcal{M}$은 마스킹된 위치의 집합. BERT의 [MASK] 예측이 곧 denoising step이다.
MDLM(Sahoo et al., 2024)도 이 구조다 — 학습된 continuous-time noise schedule $\beta(t)$를 쓰지만, 핵심 메커니즘은 같다.
그래서 klue/bert-base(한국어)와 bert-base-uncased(영어)를 iterative unmasking engine으로 사용했다.
결정화 궤적
문장 $s = (t_1, \ldots, t_S)$에 대해:
- 모든 content 토큰을 $[\text{MASK}]$로 치환: $x^{(0)} = ([\text{MASK}], \ldots, [\text{MASK}])$
- 매 step $k$에서, 모델이 각 위치 $i$의 확률 분포 $P_\theta(v \mid x^{(k)})$를 예측
- 각 위치의 confidence (확신도)와 entropy (불확실성)를 기록:
$$c_i^{(k)} = \max_v P_\theta(v \mid x^{(k)}) \qquad H_i^{(k)} = -\sum_v P_\theta(v \mid x^{(k)}) \log_2 P_\theta(v \mid x^{(k)})$$
- 아직 마스킹된 위치 중 $c_i^{(k)}$가 가장 높은 위치를 unmask: $x_i^{(k+1)} = \arg\max_v P_\theta(v \mid x^{(k)})$
- 모든 토큰이 복원될 때까지 반복 ($k = 1, \ldots, K$ where $K = S$)
이렇게 하면 문장마다 “denoising heatmap”이 생긴다. X축은 토큰 위치 $i$, Y축은 denoising step $k$. 색은 entropy $H_i^{(k)}$ (밝은색 = 높은 불확실성, 어두운색 = 확정됨).
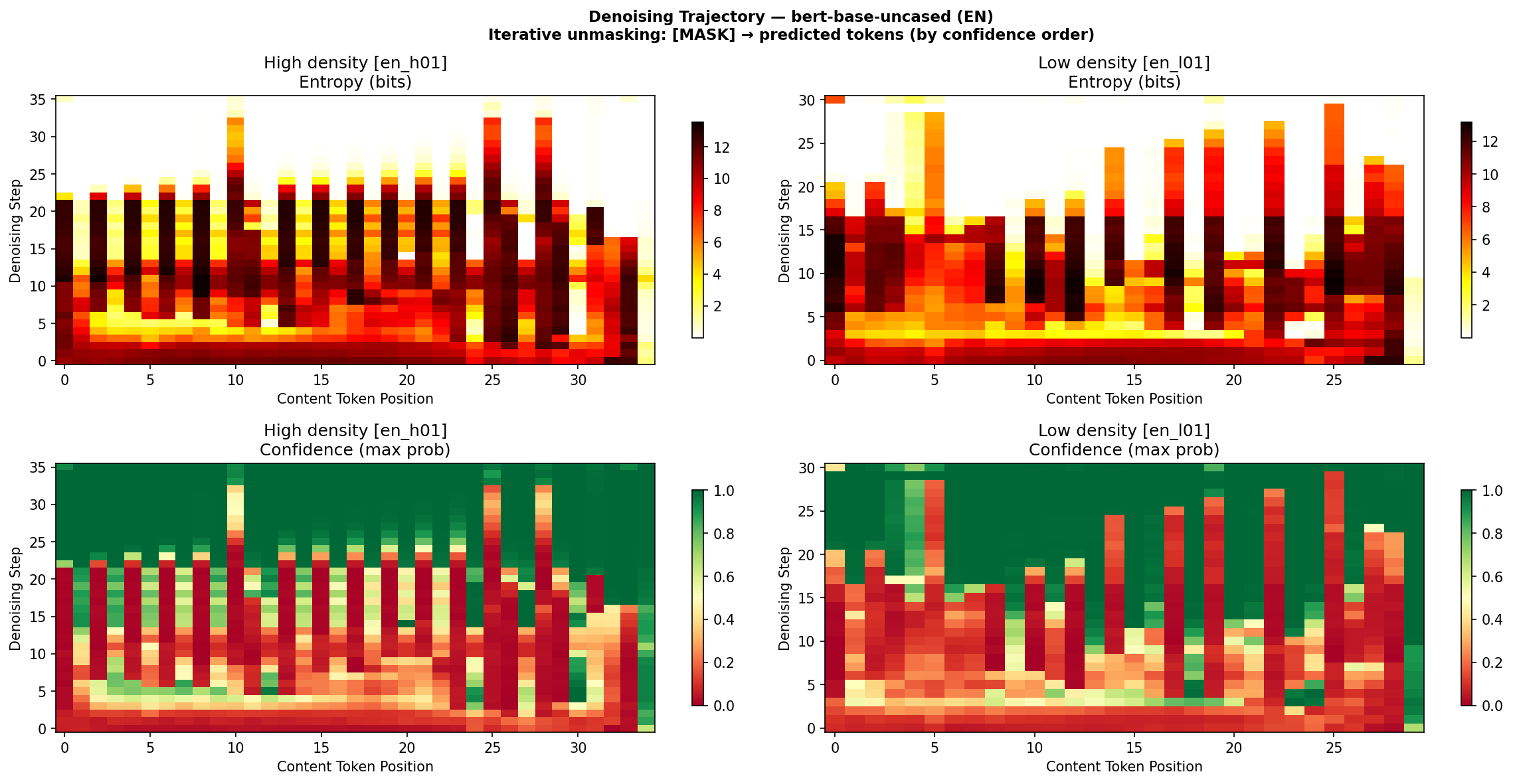 Figure 1: bert-base-uncased 영어 문장의 denoising heatmap. 위: entropy, 아래: confidence. 고밀도 문장(왼쪽)이 더 오래 불확실한 상태를 유지한다.
Figure 1: bert-base-uncased 영어 문장의 denoising heatmap. 위: entropy, 아래: confidence. 고밀도 문장(왼쪽)이 더 오래 불확실한 상태를 유지한다.
두 가지 지표
Mean Crystallization — 토큰 $i$의 결정화 시점 $\kappa_i$는 해당 토큰이 unmask되는 step 번호다. 문장 수준의 결정화:
$$\bar{\kappa} = \frac{1}{S}\sum_{i=1}^{S} \frac{\kappa_i}{K}$$
$\bar{\kappa} \approx 0$이면 대부분의 토큰이 즉시 확정, $\bar{\kappa} \approx 1$이면 끝까지 불확실.
Convergence Area — 평균 entropy 곡선 아래 면적. 전체 denoising 과정의 총 불확실성:
$$A = \int_0^1 \bar{H}(t), dt, \qquad \bar{H}(t) = \frac{1}{S}\sum_{i=1}^{S} H_i^{(\lfloor tK \rfloor)}$$
$A$가 크면 전체 과정에서 불확실성이 오래 높게 유지됨 = 복원이 어려운 문장.
파일럿 결과: 영어에서 가설이 맞았다
처음에는 n=5(고밀도 5문장, 저밀도 5문장)로 실험했다. 파일럿 결과는 이랬다:
| 모델 | 지표 | 방향 | p값 |
|---|---|---|---|
| klue/bert-base (KO) | Mean crystallization | 차이 없음 | 1.00 ns |
| klue/bert-base (KO) | Convergence area | 차이 없음 | 0.67 ns |
| bert-base-uncased (EN) | Mean crystallization | 차이 없음 | 0.67 ns |
| bert-base-uncased (EN) | Convergence area | High > Low | 0.011 * |
영어 고밀도 문장의 convergence area가 유의미하게 더 크다.
모델이 고밀도 영어 문장을 복원할 때, 전체 과정에 걸쳐 더 많은 불확실성을 경험한다. 문장 안에 담긴 정보가 많으니, “이 자리에 뭐가 올까?”를 결정하기가 더 어려운 것이다.
한국어에서는 두 지표 모두 유의미하지 않았다. 왜 그런지는 나중에 다시 돌아오겠다.
흥미로운 단서였다. 하지만 n=5. 이 결과를 믿어도 되는가?
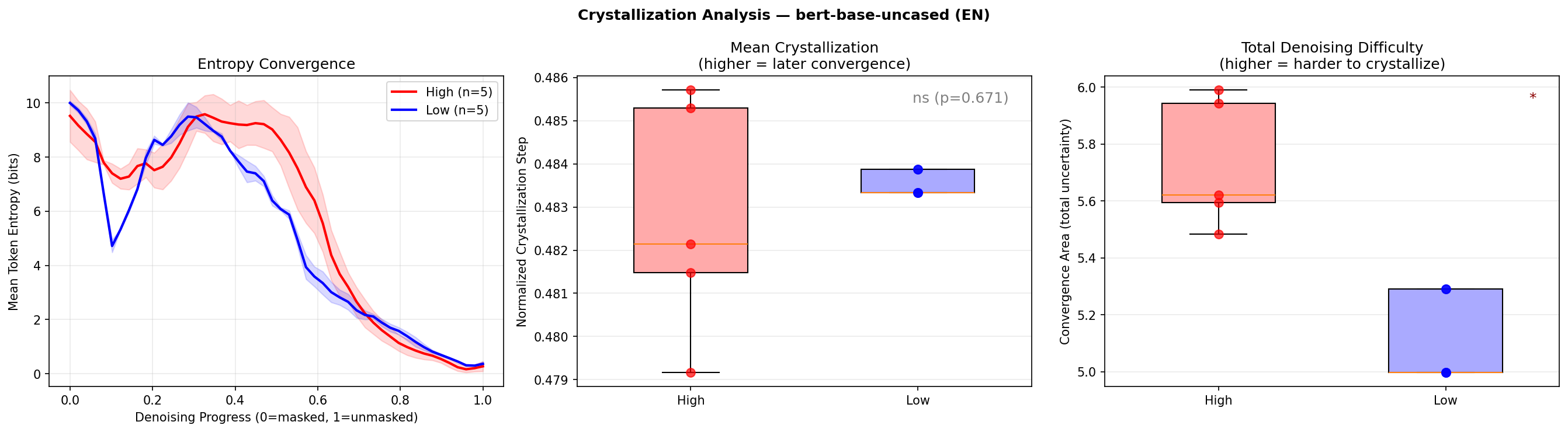 Figure 2: 영어 문장의 entropy 수렴 곡선과 결정화 분포. 고밀도 문장(빨간색)이 더 높은 convergence area를 보인다.
Figure 2: 영어 문장의 entropy 수렴 곡선과 결정화 분포. 고밀도 문장(빨간색)이 더 높은 convergence area를 보인다.
검증이 필요하다
Part 1의 파일럿 실험에는 두 가지 구조적 문제가 있었다.
첫째, 표본 크기. n=5 per group. 유의미한 결과가 나온 것 자체가 다행이지만, 효과 크기의 신뢰구간이 너무 넓다. p=0.032도 n=5에서는 겨우 잡힌 것이다.
둘째, 교락 변수. 고밀도 문장은 격언과 인용구였고, 저밀도 문장은 일상 서술이었다. Probing classifier가 모든 레이어에서 100% 정확도를 보였는데, PCA 1개 주성분만으로 완벽 분리가 가능했다. 이건 모델이 “밀도”를 보는 게 아니라 “격언 vs 일상문”의 문체를 보고 있을 가능성을 의미한다.
Layer Delta와 Surprisal CV는 “처리 방식의 차이”를 측정하는 신호이므로 문체 효과와는 구분되지만, 그래도 확인이 필요했다.
그래서 두 가지 검증 실험을 설계했다.
검증 실험 1: 확대 코퍼스 (general.csv)
한국어 50문장(고밀도 25, 저밀도 25), 영어 50문장(고밀도 25, 저밀도 25). 총 100문장.
고밀도 문장은 파일럿에서와 같은 유형 — 압축된 격언/경구 스타일. 저밀도 문장은 동일한 주제를 풀어쓴 일상 서술. 예를 들어:
| 고밀도 | 저밀도 |
|---|---|
| 늦은 준비는 빠른 후회를 부른다. | 시험 전날에 공부를 시작하면 모든 내용을 충분히 복습하기 어렵다. |
| Late preparation breeds early regret. | If you start studying the night before an exam you usually cannot review all of the material carefully. |
Mann-Whitney U 검정(독립표본, n=25/group). 결과:
| 신호 | 언어 | 방향 | p값 |
|---|---|---|---|
| Layer Delta | KO | High > Low | 0.003** |
| Layer Delta | EN | High > Low | 0.0001*** |
| Surprisal Mean | KO | High > Low | < 0.0001*** |
| Surprisal Mean | EN | High > Low | < 0.0001*** |
| Surprisal CV | KO | High < Low | < 0.0001*** |
| Surprisal CV | EN | High < Low | 0.003** |
| Convergence Area | KO | = | 0.94 ns |
| Convergence Area | EN | High > Low | < 0.0001*** |
파일럿에서 나타난 모든 경향이 확인되었다. 그리고 더 중요한 것들이 새로 드러났다.
파일럿에서 보이지 않았던 것이 나타났다. 영어 Layer Delta는 파일럿에서 유의미하지 않았는데 ($p > 0.05$), 표본을 25로 늘리자 $p = 0.0001$로 강하게 유의미해졌다. 영어 Surprisal CV도 마찬가지 ($p = 0.003$). n=5에서는 효과를 검출할 검정력이 없었던 것이다.
영어 Convergence Area가 폭발적으로 강해졌다. 파일럿의 $p = 0.011$이 $p < 0.0001$로. 이건 우연이 아니었다.
한국어 Convergence Area는 여전히 null. $p = 0.94$. 표본을 5배 늘려도 꿈쩍도 안 한다. 이건 검정력 부족이 아니라, 진짜로 효과가 없는 것이다.
검증 실험 2: Minimal Pairs (100쌍)
교락 변수 문제를 정면으로 해결하기 위해, 같은 의미를 다른 밀도로 표현한 문장 쌍을 만들었다. 한국어 50쌍, 영어 50쌍. 예:
| 저밀도 (풀어쓴 표현) | 고밀도 (압축 표현) |
|---|---|
| 발표 전에 충분히 준비하지 않으면 질문을 받을 때 제대로 답하기 어렵다 | 준비 없는 발표는 질문 앞에서 흔들린다 |
| 파일을 백업하지 않은 채 시스템을 업데이트하면 중요한 문서를 잃을 수 있다 | 백업 없는 업데이트는 문서 손실을 부른다 |
| If you do not prepare enough before a presentation it is hard to answer questions well | An unprepared presentation falters under questions |
| If you keep too many browser tabs open your laptop can slow down | Too many tabs drag the laptop |
이 설계의 핵심: 두 문장이 전달하는 명제는 같다. 다른 건 표현의 압축도뿐. 이걸 구문적 압축(syntactic compression)이라고 부른다. 파일럿의 일반 코퍼스가 측정한 명제적 밀도(propositional density)와는 다른 축이지만, “같은 내용을 더 적은 토큰으로 표현했을 때 모델이 다르게 반응하는가?”를 직접 묻는 것이다.
Wilcoxon signed-rank test(대응표본, n=50 pairs/lang). 결과:
| 신호 | 언어 | 방향 | p값 |
|---|---|---|---|
| Layer Delta | KO | High > Low | 0.005** |
| Layer Delta | EN | High > Low | < 0.0001*** |
| Surprisal Mean | KO | High > Low | < 0.0001*** |
| Surprisal Mean | EN | High > Low | < 0.0001*** |
| Surprisal CV | KO | High < Low | < 0.0001*** |
| Surprisal CV | EN | High < Low | < 0.0001*** |
| Convergence Area | KO | = | 0.44 ns |
| Convergence Area | EN | High > Low | < 0.0001*** |
의미를 통제해도 결과가 같다.
이건 중요하다. 파일럿에서 “격언이니까 Layer Delta가 큰 거 아냐?” 하는 의심이 있었다. 하지만 같은 뜻을 말하는 두 문장 — “발표 전에 충분히 준비하지 않으면…”과 “준비 없는 발표는 질문 앞에서 흔들린다” — 에서도 압축된 쪽의 Layer Delta가 유의미하게 더 크다. 모델은 문체가 아니라, 텍스트 압축 자체에 반응하고 있다.
그리고 한국어 Convergence Area는 다시 한번 null ($p = 0.44$). 이 패턴은 이제 우연이 아니다.
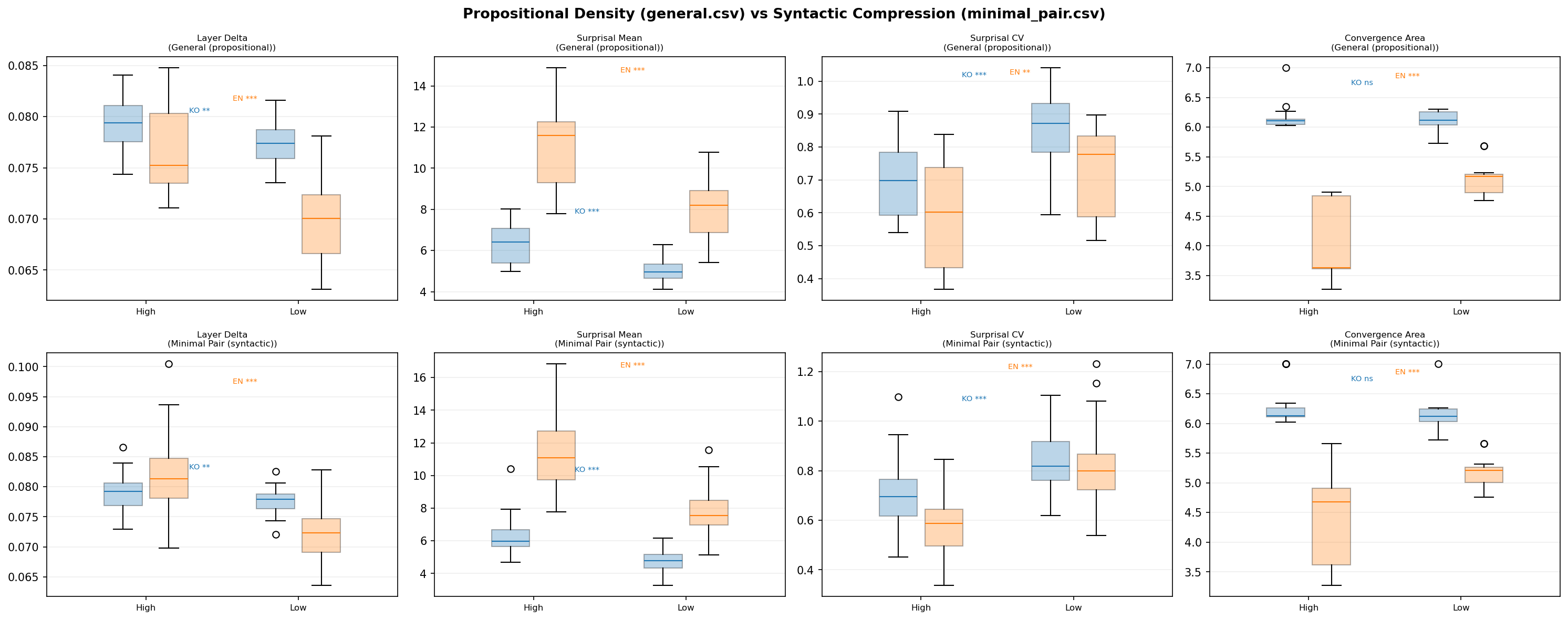 Figure 3: 명제적 밀도(general) vs 구문적 압축(minimal pair) — 두 조건 모두에서 영어 convergence area의 유의미한 차이가 관찰되었다.
Figure 3: 명제적 밀도(general) vs 구문적 압축(minimal pair) — 두 조건 모두에서 영어 convergence area의 유의미한 차이가 관찰되었다.
한국어 Diffusion은 왜 안 보이는가
세 번의 실험(파일럿, 확대 코퍼스, minimal pair)에서 일관되게 한국어 convergence area는 밀도와 무관했다. 이건 분명한 null result이다. 왜?
1. SOV 구조의 문제. 한국어는 동사가 문장 끝에 온다. Iterative unmasking에서 모델은 “가장 확신하는 위치”부터 복원하는데, 한국어에서는 내용어(명사, 형용사)가 먼저 복원되고 조사/어미가 나중에 온다. 이 순서는 문장의 밀도와 관계없이 항상 비슷할 수 있다.
“준비 없는 발표는 질문 앞에서 흔들린다” — 여기서 “준비”, “발표”, “질문”은 빨리 복원되고, “없는”, “앞에서”, “흔들린다”는 나중에 온다. “발표 전에 충분히 준비하지 않으면 질문을 받을 때 제대로 답하기 어렵다” — 여기서도 “발표”, “준비”, “질문”이 먼저 복원된다. 복원 패턴이 밀도에 의해 달라지지 않는 것이다.
반면 영어는 SVO 구조에서 주어-동사-목적어가 정보 밀도에 따라 더 다양한 복원 순서를 만들어낼 수 있다.
2. BERT의 MLM head 특성. klue/bert-base의 MLM head가 한국어 토큰 예측에서 밀도 민감도가 낮을 수 있다. Forward pass(내부 표현)에서는 차이가 보이지만(Layer Delta p=0.003), 출력층(토큰 예측 확률)에서는 안 보이는 것.
이건 흥미로운 해리(dissociation)다. 같은 BERT 모델이 한국어에서:
- Forward pass 신호 (Layer Delta): 밀도에 반응한다 (p=0.003)
- Reverse process 신호 (Convergence Area): 밀도에 반응하지 않는다 (p=0.94)
모델이 “이해”하는 것과 “복원”하는 것이 다른 채널을 쓰고 있을 가능성.
신호들은 서로 연결되어 있다
100문장 규모의 데이터가 생기면서 할 수 있게 된 분석이 있다: 신호 간 상관. Layer Delta가 높은 문장은 Surprisal도 높은가? Convergence Area와는 어떤 관계인가?
영어에서 가장 강력한 상관이 나타났다:
$$\text{Surprisal Mean} \leftrightarrow \text{Convergence Area}: \quad \rho = -0.624, \quad p < 0.0001$$
Surprisal Mean이 높은 문장(= Decoder가 예측하기 어려운 문장)은 Convergence Area가 크다(= Diffusion으로 복원하기도 어렵다). 음의 상관인 이유는 convergence area의 방향 정의 때문이지만, 의미는 명확하다:
“예측이 어렵다” $\approx$ “복원이 어렵다.”
Decoder가 왼쪽에서 오른쪽으로 다음 토큰을 예측하는 것과, Diffusion 모델이 전체 마스크에서 토큰을 복원하는 것은 — 완전히 다른 알고리즘이지만 — 같은 난이도를 다른 각도에서 보고 있다.
한국어에서는 다른 흥미로운 상관이 나타났다:
$$\text{Layer Delta} \leftrightarrow \text{Surprisal Mean}: \quad \rho = 0.378, \quad p = 0.007$$
Layer Delta가 큰 문장(= Encoder가 더 많이 변환하는 문장)은 Surprisal도 높다(= Decoder도 예측이 어렵다). Encoder의 “처리 노력”과 Decoder의 “예측 난이도”가 같은 방향을 가리킨다.
이 교차 상관은 세 패러다임의 신호가 서로 독립이 아니라는 것을 보여준다. 밀도라는 하나의 속성이 Encoder/Decoder/Diffusion에서 각각 다른 형태로 발현되지만, 근본적으로 연결되어 있다.
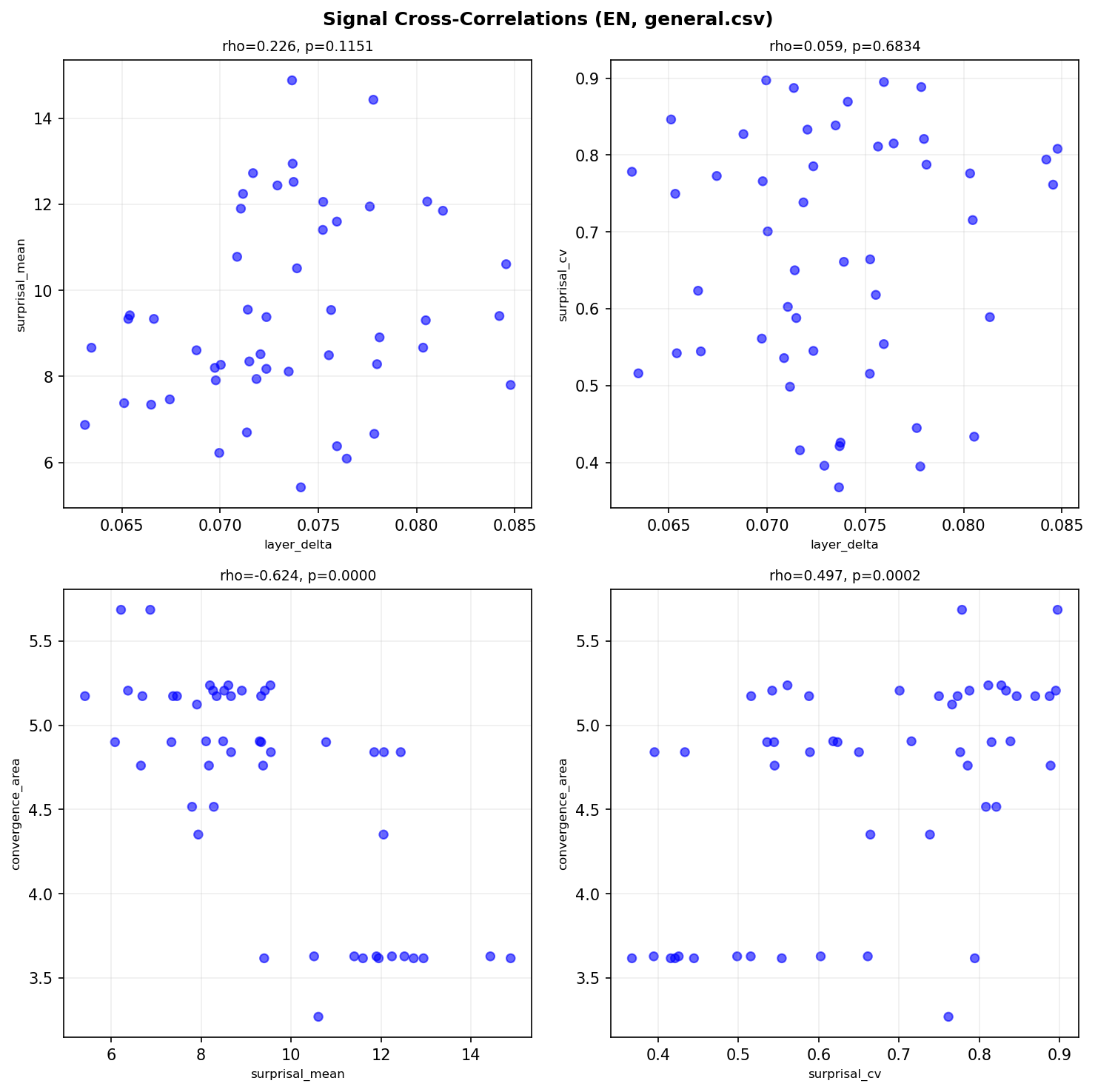 Figure 4: 영어 신호 간 교차 상관. Surprisal Mean ↔ Convergence Area (ρ=-0.624**)가 ‘예측 난이도 ≈ 복원 난이도’를 확인한다.*
Figure 4: 영어 신호 간 교차 상관. Surprisal Mean ↔ Convergence Area (ρ=-0.624**)가 ‘예측 난이도 ≈ 복원 난이도’를 확인한다.*
Part 1의 발견은 재현되었다
파일럿(n=5)에서 발견한 것들이 검증에서 어떻게 됐는지 정리하자.
Encoder의 Layer Delta (High > Low):
- 파일럿: KO p=0.032*, EN ns
- 검증(general): KO p=0.003**, EN p=0.0001***
- 검증(pair): KO p=0.005**, EN p<0.0001***
- 재현됨. 영어도 유의미해짐.
Decoder의 Surprisal CV (High < Low):
- 파일럿: KO p=0.008**, EN ns
- 검증(general): KO p<0.0001***, EN p=0.003**
- 검증(pair): KO p<0.0001***, EN p<0.0001***
- 재현됨. 영어도 유의미해짐. UID 가설이 양 언어에서 확인됨.
Diffusion의 Convergence Area (영어 High > Low):
- 파일럿: EN p=0.011*
- 검증(general): EN p<0.0001***
- 검증(pair): EN p<0.0001***
- 재현됨. 훨씬 강해짐.
한국어 Diffusion Null:
- 파일럿: KO p=0.67 ns
- 검증(general): KO p=0.94 ns
- 검증(pair): KO p=0.44 ns
- 일관된 null. 이건 진짜 없다.
이 실험이 답하지 못한 것
파일럿에서 지적했던 한계 중 일부는 해결되었고, 일부는 남아있다.
[해결됨] 표본 크기. n=5에서 n=25(general)과 n=50 pairs(minimal pair)로 확대했다. 파일럿의 모든 유의미한 결과가 더 강하게 재현되었다. 파일럿에서 놓쳤던 영어 Layer Delta와 영어 Surprisal CV도 표본 확대 후 유의미해졌다.
[부분적으로 해결됨] 밀도 vs 문체. Minimal pair 실험으로 구문적 압축을 통제했다. 같은 명제를 다른 길이로 표현했을 때도 모델이 반응한다는 것을 확인했다. 하지만 이건 “같은 뜻, 다른 길이”이지 “다른 뜻, 같은 길이”는 아니다. 명제적 밀도 — 같은 길이에 더 많은 명제가 담긴 문장 — 를 문체를 완전히 통제하면서 테스트하려면, 추가 실험이 필요하다.
[미해결] 진짜 Diffusion LM. BERT iterative unmasking은 이론적으로 D3PM과 동치이지만, MDLM처럼 학습된 noise schedule을 쓴 모델과의 직접 비교는 CUDA GPU가 필요하다.
[미해결] 인과관계. “밀도가 높으니까 Layer Delta가 크다”인지, “어려운 문장이니까 Layer Delta가 크다”인지는 여전히 구분하지 못했다. 밀도와 난이도를 교차시킨 2x2 실험 설계가 필요하다 — 밀도가 높지만 쉬운 문장, 밀도가 낮지만 어려운 문장을 만들어야 한다.
[미해결] 한국어 SOV와 Diffusion. 한국어 Convergence Area가 왜 일관되게 null인지에 대한 설명은 가설 수준이다. 한국어 SOV 구조가 iterative unmasking의 복원 순서에 어떤 영향을 미치는지 직접 분석하려면, 복원 순서 자체를 밀도별로 비교하는 추가 실험이 필요하다.
전체 정리: Part 1 + Part 2를 관통하는 이야기
이 실험 시리즈에서 알게 된 것을 처음부터 끝까지 정리한다.
PER: 밀도를 측정하는 새로운 도구
Paraphrase Expansion Ratio — LLM에게 “초등학생이 이해할 수 있게 풀어써”라고 시키고, 원문 대비 토큰 수 비율을 잰다.
$$\text{PER}(s) = \frac{|\text{tokens}(\text{paraphrase}(s))|}{|\text{tokens}(s)|}$$
6개 LLM으로 교차 검증한 결과, GPT와 Claude는 어떤 문장이 더 dense한지 서로 동의하지만 ($\rho = 0.74 \sim 0.88$), Gemini는 완전히 다른 기준을 적용한다 ($\rho = -0.14 \sim 0.19$). PER은 절대값이 아닌 상대적 순위로 사용해야 한다.
세 패러다임의 밀도 반응
세 가지 트랜스포머 패러다임으로 텍스트 밀도를 관찰했다. 검증 실험의 결과를 포함한 최종 요약:
| 패러다임 | 대표 신호 | KO general | KO pair | EN general | EN pair |
|---|---|---|---|---|---|
| Encoder | Layer $\delta$ | .003** | .005** | .0001*** | <.0001*** |
| Decoder | Surp. CV | <.0001*** | <.0001*** | .003** | <.0001*** |
| Diffusion | Conv. A | .94 ns | .44 ns | <.0001*** | <.0001*** |
Encoder (BERT, bidirectional): 문장 전체를 동시에 보는 모델. 고밀도 문장에서 Layer Delta가 더 크다. 검증 실험에서 한국어($p=0.003$)와 영어($p=0.0001$) 모두 유의미. Minimal pair에서도 재현($p=0.005$, $p<0.0001$). 해석: 압축된 의미를 펼치려면 레이어마다 더 많은 변환이 필요하다.
Decoder (Qwen3, causal): 토큰을 왼쪽에서 오른쪽으로 처리하는 모델. 고밀도 문장에서 surprisal의 변동계수(CV)가 더 낮다. 양 언어에서 강하게 유의미($p < 0.0001$). 고밀도 문장은 정보가 토큰들에 고르게 배분된다. 해석: UID(Uniform Information Density) 가설 — 잘 압축된 문장은 정보 전달률을 균일하게 유지한다.
Diffusion (BERT as denoiser): 전체를 파괴한 뒤 복원하는 모델. 영어에서만 고밀도 문장의 총 불확실성이 더 높다($p < 0.0001$). 한국어에서는 세 번 모두 null. 해석: 밀도 높은 영어 문장은 복원 과정에서 더 오래 “불확실한 상태”를 유지한다. 한국어에서는 SOV 구조의 특성으로 이 신호가 발현되지 않을 가능성이 있다.
”어렵다”의 세 가지 얼굴
세 패러다임이 모두 같은 방향을 가리킨다: 밀도는 모델에게 “더 어렵다.” 하지만 “어렵다”의 의미가 패러다임마다 다르다:
- Encoder한테는 “더 많은 변환이 필요하다” (Layer Delta $\uparrow$)
- Decoder한테는 “예측이 균일하게 어렵다” (Surprisal CV $\downarrow$, Mean $\uparrow$)
- Diffusion한테는 “복원에 더 많은 불확실성이 남는다” (Convergence Area $\uparrow$)
그리고 이 세 가지 “어려움”은 서로 독립이 아니다. 영어에서 Surprisal Mean과 Convergence Area의 상관 $\rho = -0.624$ ($p < 0.0001$)은, 예측 난이도와 복원 난이도가 같은 근원을 공유한다는 것을 보여준다.
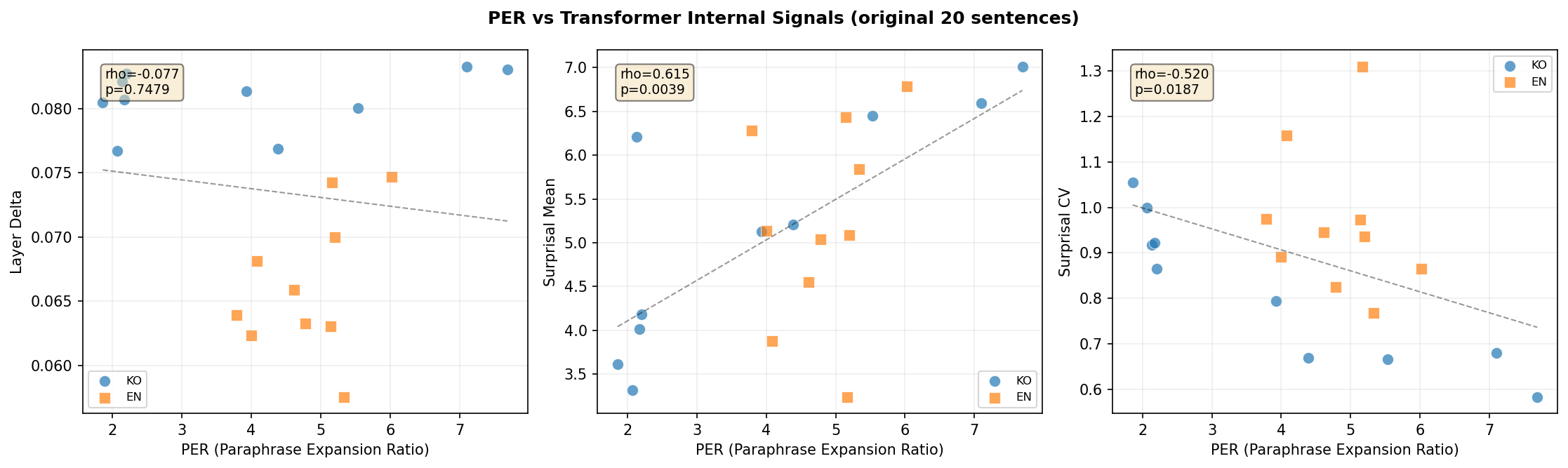 Figure 5: PER과 내부 신호 간 상관. PER이 높을수록 surprisal이 높고(ρ=0.867) CV는 낮다(ρ=-0.952).
Figure 5: PER과 내부 신호 간 상관. PER이 높을수록 surprisal이 높고(ρ=0.867) CV는 낮다(ρ=-0.952).
한국어 vs 영어: 비대칭의 의미
한국어와 영어의 결과가 비대칭인 건 Diffusion뿐이다. Encoder와 Decoder 신호는 양 언어에서 모두 유의미하다. 이건 밀도가 언어 보편적인 속성임을 시사한다 — 어떤 언어로 쓰든, 압축된 문장은 모델이 더 열심히 처리한다.
Diffusion의 비대칭은 밀도 자체의 문제가 아니라, 분석 방법(iterative unmasking)과 언어 구조(SOV vs SVO) 사이의 상호작용에서 오는 것으로 보인다.
마지막 생각
사람도 밀도 높은 글을 한 번에 이해하지 못한다. 부르크하르트의 “혁명이 숙적을 주인으로 만들지 않는다면 그것만으로도 행운이다”를 읽으면, 잠시 멈추고, 몇 번 다시 읽고, 자기 경험에 비춰서 해석한다.
트랜스포머도 비슷한 일을 하는 걸까? Layer Delta가 큰 것은 “각 레이어에서 더 많이 생각한다”는 뜻이고, Surprisal CV가 낮은 것은 “문장 전체에 걸쳐 고르게 집중한다”는 뜻이다. Convergence Area가 큰 것은 “복원 과정에서 더 오래 확신을 갖지 못한다”는 뜻이다.
물론 모델이 “이해”하는 건 아니다. 하지만 밀도라는 속성이 모델의 내부 처리에 흔적을 남긴다는 건 — 파일럿(20문장)에서 발견하고, 확대 코퍼스(100문장)에서 확인하고, 의미를 통제한 minimal pair(100쌍)에서 재현함으로써 — 이제 꽤 확신할 수 있다.
그 흔적의 모양이 패러다임마다 다르다는 것도. 그리고 그 다른 모양들이 서로 연결되어 있다는 것도.
글에 밀도가 있다는 건 — 아마도 글쓴이가 그만큼 많은 생각을 압축했다는 뜻일 것이다. 그리고 그 압축을 풀려면, 읽는 쪽에서도 그만큼의 노력이 필요하다. 사람이든 모델이든.